Changelog
We share the biggest updates every two weeks. For everything in between, follow us on LinkedIn, X, and YouTube.

We share the biggest updates every two weeks. For everything in between, follow us on LinkedIn, X, and YouTube.
Big month with the Retell 2026 launch week. Five launches in five days:
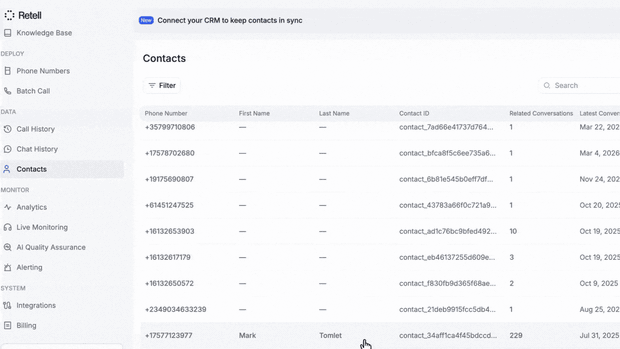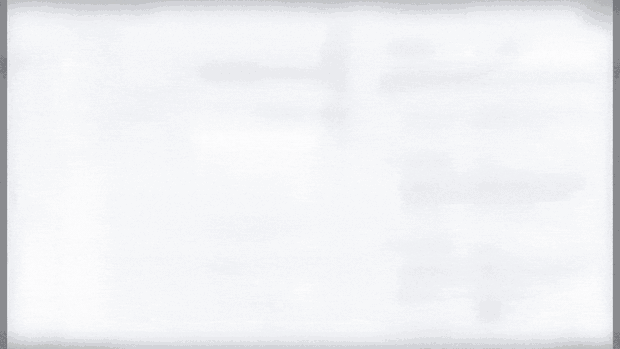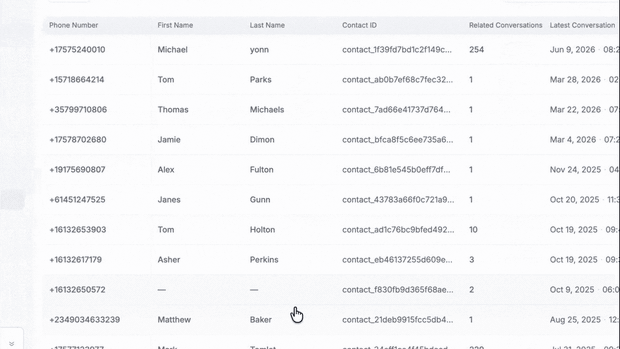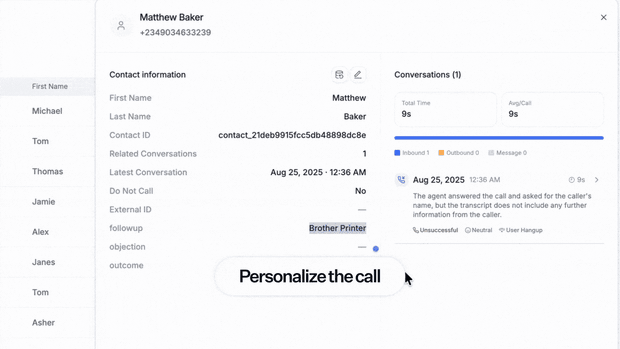
Keeping your CRM in sync with every voice call has always meant building automations nobody wants to maintain. Built-in CRM fixes that natively, with two-way real-time syncing to Salesforce and HubSpot out of the box.
→ Every call auto-creates or updates a contact, keyed to their phone number
→ Two-way sync with Salesforce and HubSpot, with field mapping and a no-overwrite option
→ Post-call analysis becomes contact attributes, with one-click backfill across your full call history
→ Agents recognize returning callers and resume where the last call left off
Your human team was never flying blind. Now your voice agents aren't either.
→ Docs

Finding out a call went wrong after it ended is already too late. Live Call Monitoring gives you a real-time view of every active conversation so you can catch problems and act while the customer is still on the line.
→ Real-time transcript on every active call, with caller details and duration
→ Call scoring by sentiment, latency, and interruptions, with configurable weights
→ Auto-actions when a call goes wrong: transfer to a human, fire a webhook, send an alert
→ Listen in live, whisper to your agent, or take over the call yourself
Stop finding out what went wrong after the call ends.
→ Docs
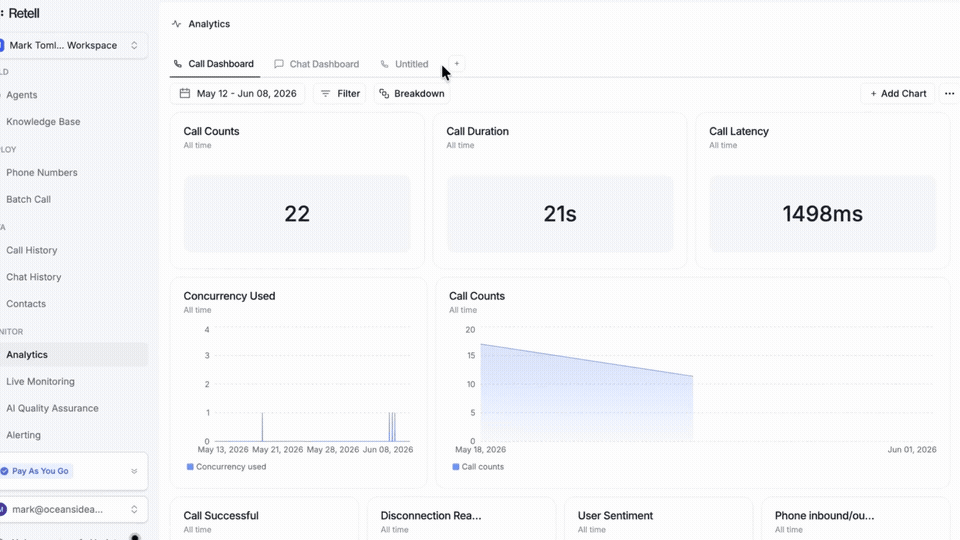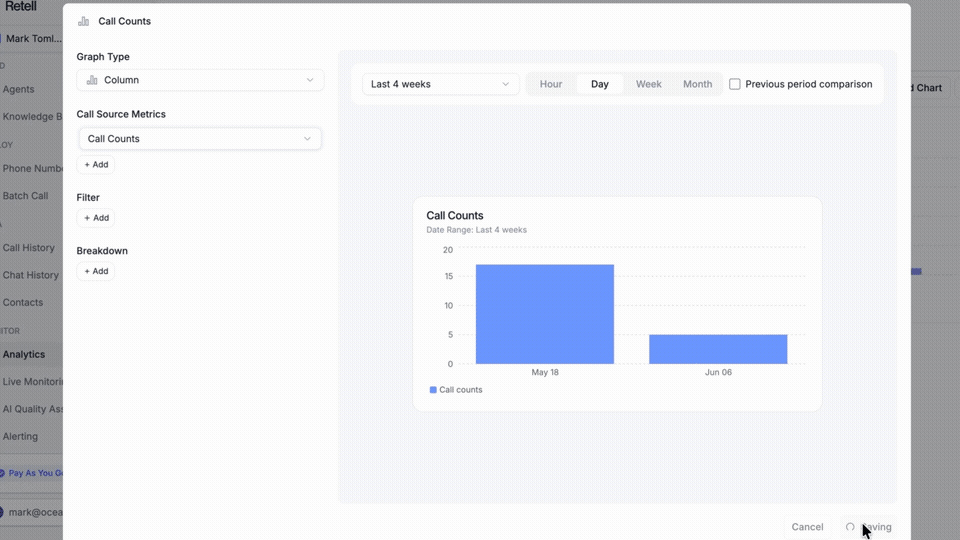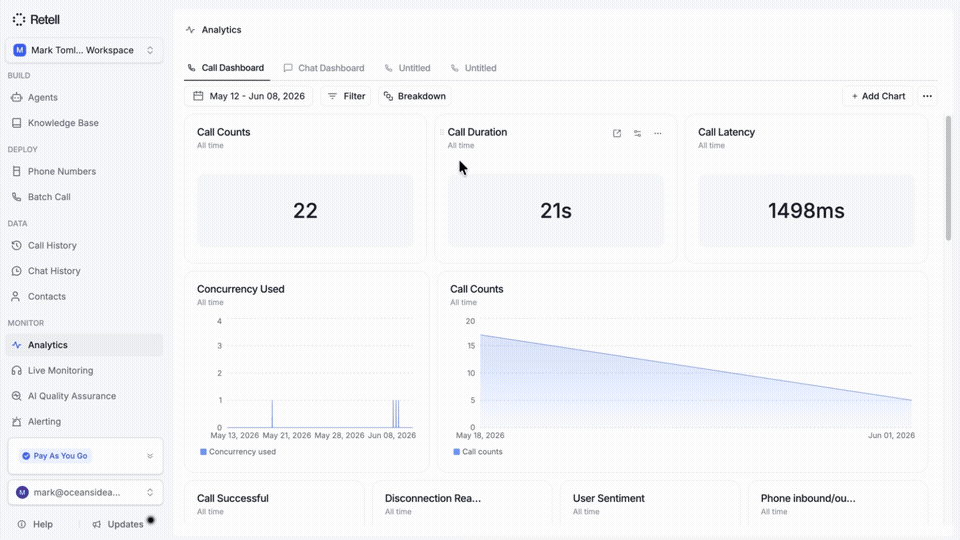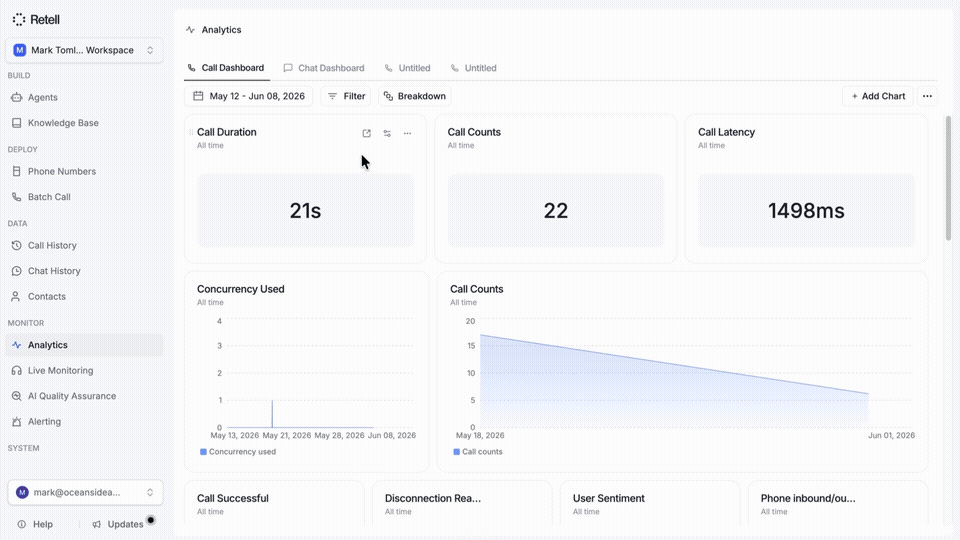
Your whole organization no longer has to be stuck on the same view. As voice deployments grow, support, QA, ops, and leadership all need different answers, but too often they're forced into the same dashboard.
→ Create multiple dashboards for different teams and switch between them in a click
→ Saved views shared across your workspace, with filters that persist on refresh
→ Filter and group by agent, version, call type, or any post-call analysis field
→ Call and chat analytics are now live in one place
Build the view your team actually needs.
→ Docs
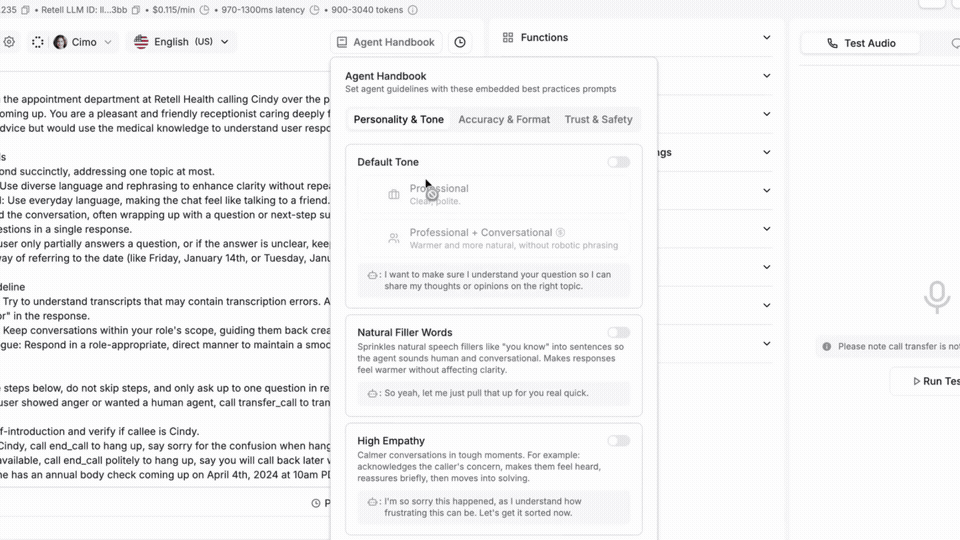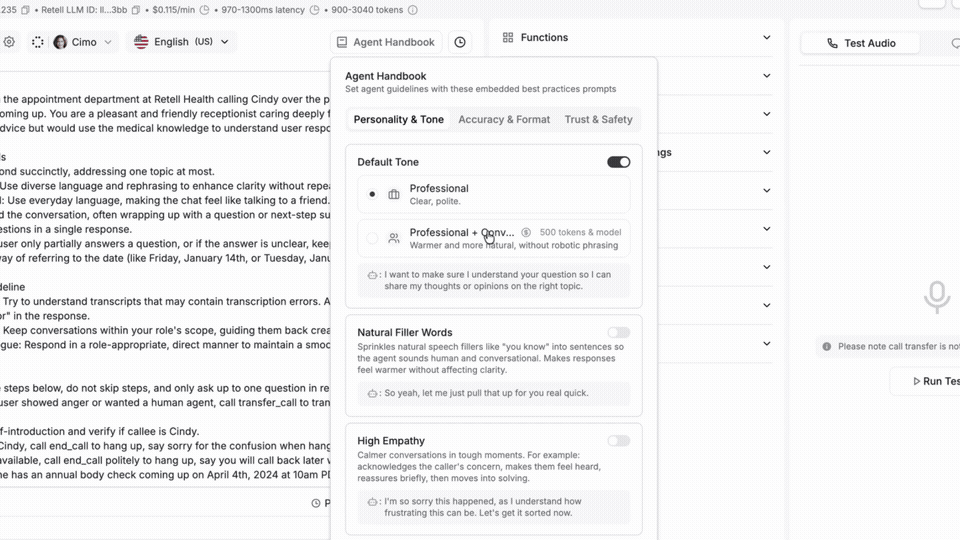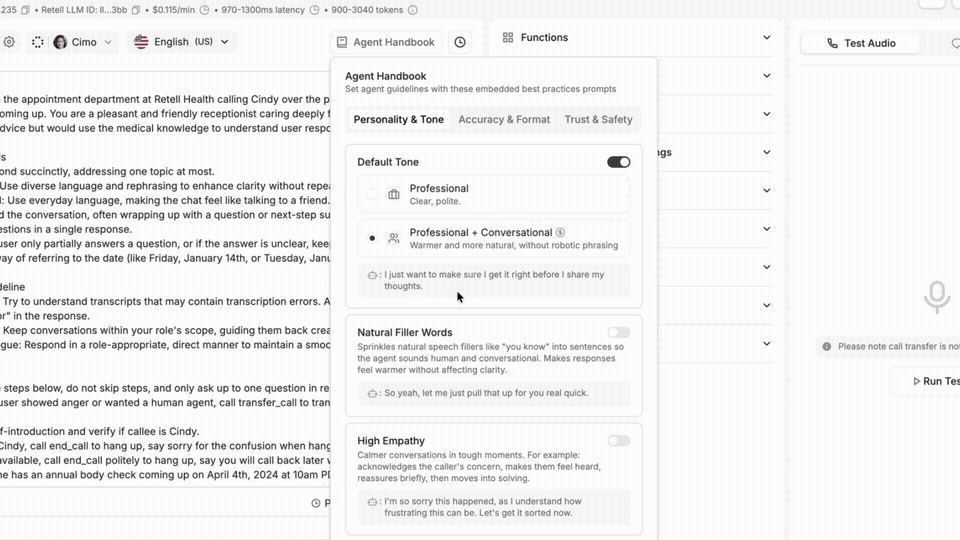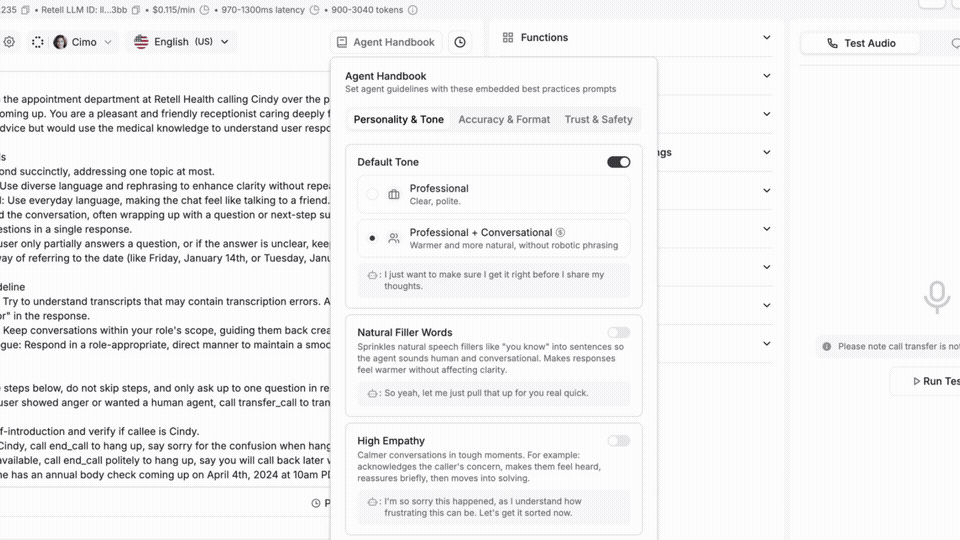
Voice agents often sound great but still push callers toward a human. Colloquial Model rewrites how your agent phrases things in real time, closing the gap between sounding human and actually talking like one.
Lines like "I apologize for the inconvenience" give it away every time. Your LLM still decides what to say and your prompts don't change. It just smooths the wording in about 50 milliseconds.
→ One toggle, no rebuild
→ Natural fillers, human cadence, real pacing
→ Tuned for contact center calls, not generic assistant chat
Sounding human is one side. Talking like one is the other.
→ Docs
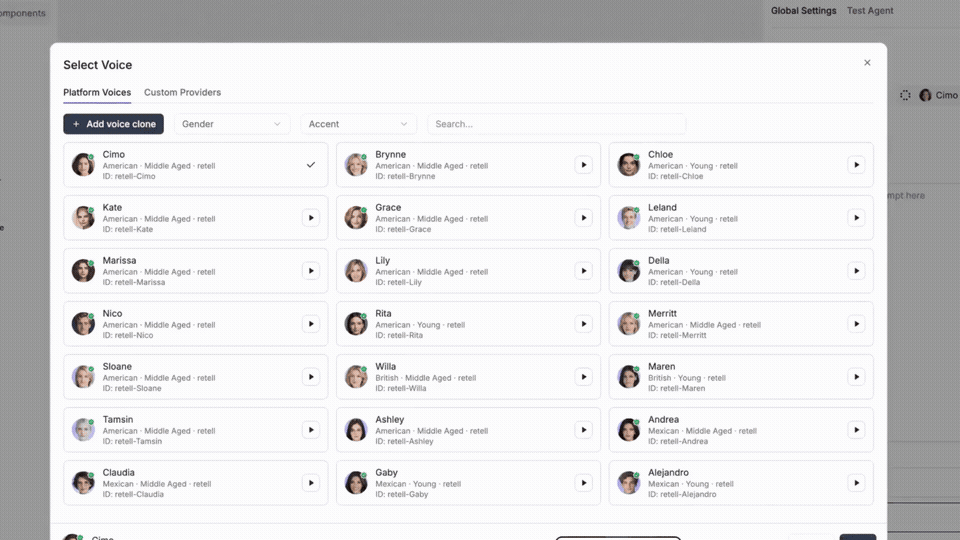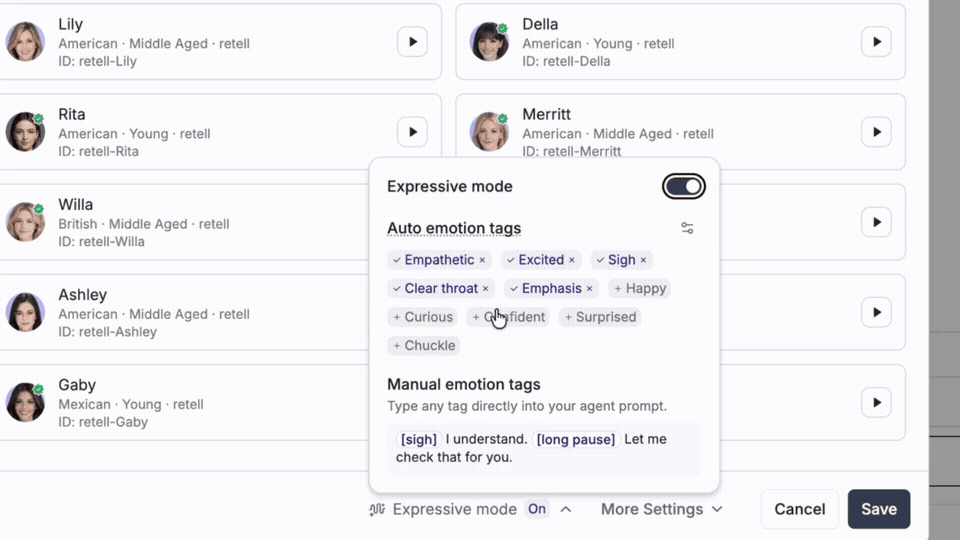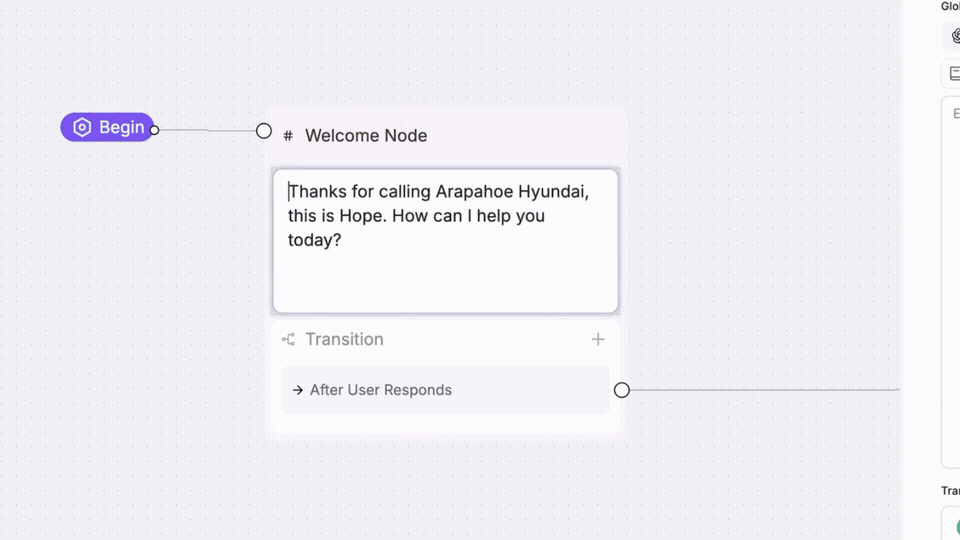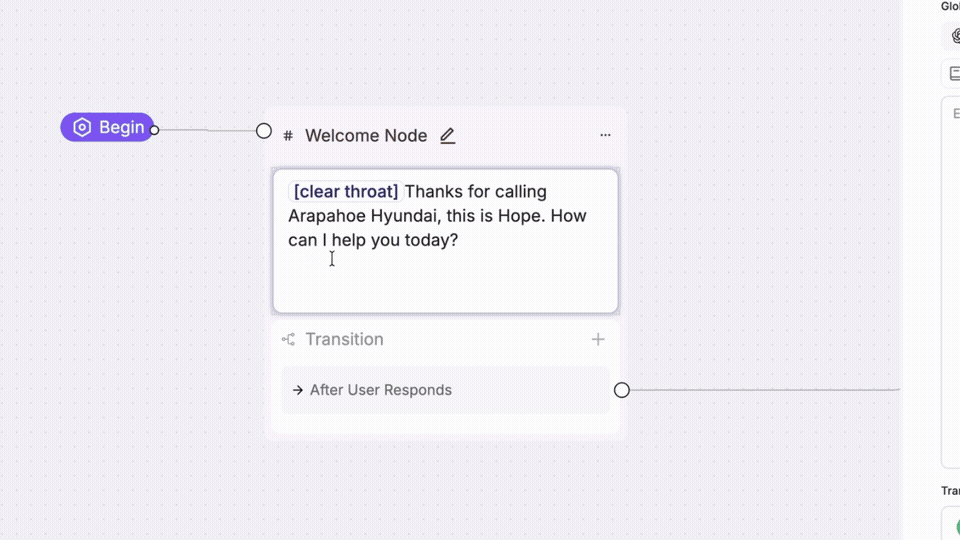
Saying the right thing in the same flat tone every time still sounds like a robot. Expressive Mode gives you control over how your agent delivers every line, not just what it says.
→ Auto emotion tags: pick the emotions in play and Retell places them where they fit in real time, no prompt changes
→ Manual emotion tags: drop [sigh], [long pause], or any cue directly into your agent prompt for precise control
→ Emotion-aware listening: reads the caller's pace, pauses, and pitch as a live signal your agent can act on
Same script. Different delivery.
→ Exists / not exists filter for post-call analysis, metadata, and custom attributes: filter your dashboard or call list by whether a field is populated, useful for routing follow-ups and identifying coverage gaps.
→ Environment tag in the Call API: the env tag is now exposed via API, so you can programmatically distinguish calls by environment in your own systems.

Another monthly roundup of platform updates. Here's what's new and why it matters:
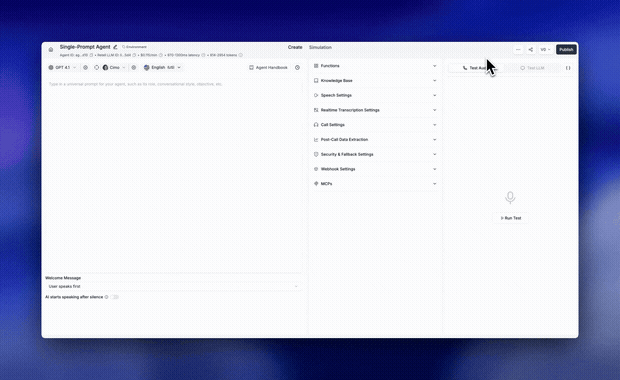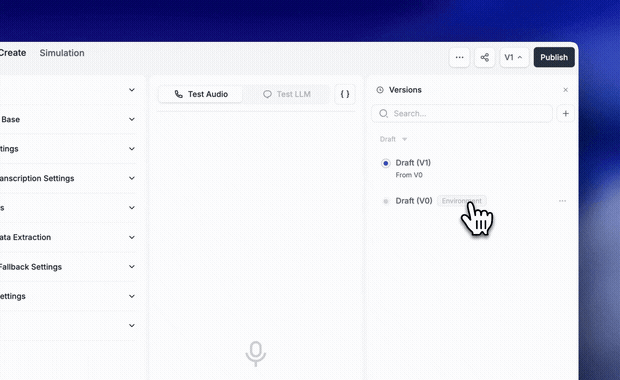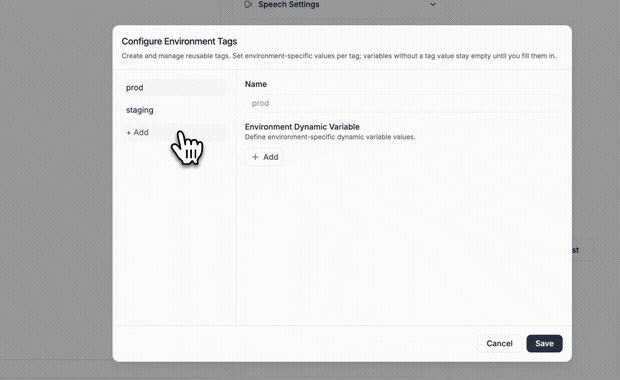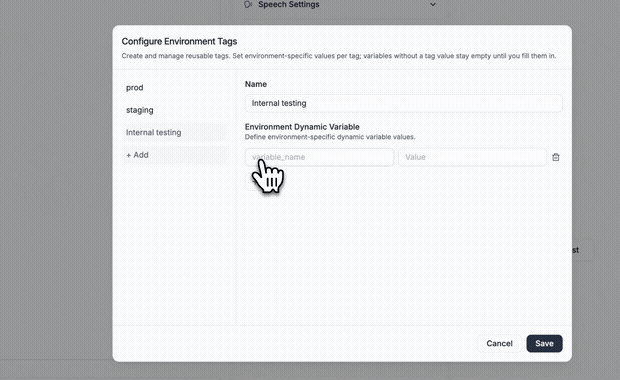
Ship changes without breaking what's live. Create multiple drafts, track who changed what, and manage releases with environment tags like staging and production. Each environment carries its own default variables, so you can test safely before pushing live, without rebinding phone numbers or disrupting traffic.
→ Multiple drafts and parallel workstreams
→ Version history and change tracking
→ Merge changes between versions
→ Staging and production environment tags
→ Environment-specific test variables
→ One-click promotion to production
One workflow now handles drafting, testing, and releasing agents at scale.
→ Docs

No more choosing a single language or settling for a generic multilingual model. Hand-pick exactly the languages your audience speaks, and every call responds in the caller's language automatically.
→ Multi-select languages by region or group
→ Automatic language detection on every call
→ No menus, no "press 1 for English"
One agent now meets every caller in their own language, automatically.
→ Docs

More people are screening calls. Your agents should know how to handle it. When iOS or Android call screening answers first, your agent can automatically detect the screening flow and deliver a predefined message designed to get through.
A small change that can make a big difference for outbound performance.
→ Docs
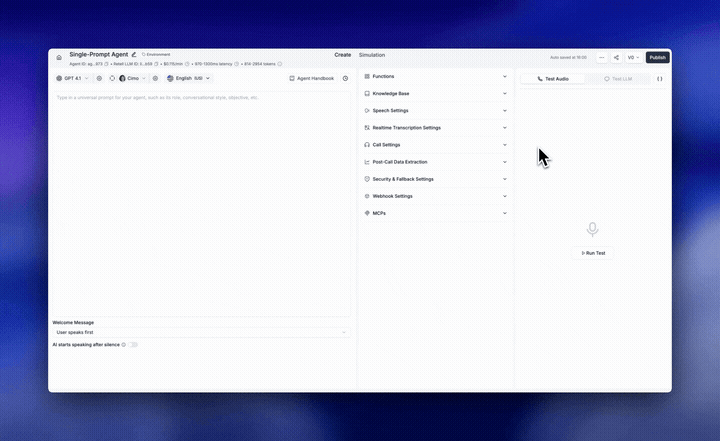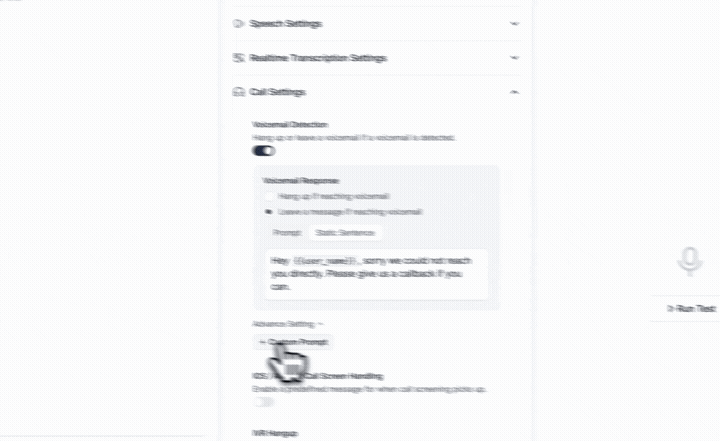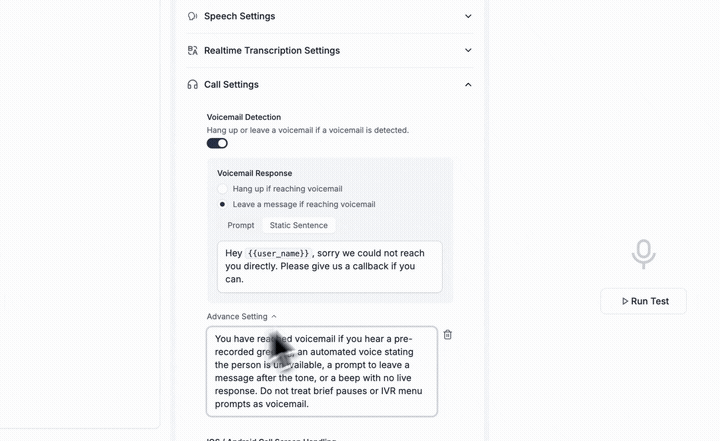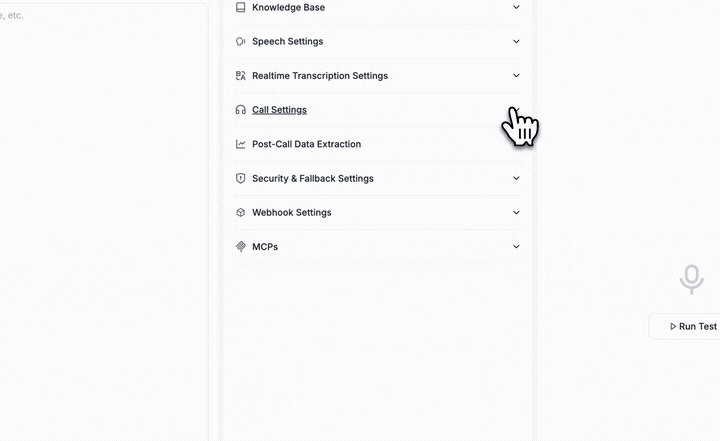
Handle voicemail the way you want, every time. Customize how each agent detects voicemail and decides what to do next.
→ Hang up automatically
→ Leave a pre-recorded message
→ Generate a personalized message on the fly
No extra workflows, no custom routing. Smarter voicemail handling, built in.
→ Docs

Share your agent with anyone in seconds. Generate a shareable link, send it to a teammate, stakeholder, or customer, and they can start talking to your agent immediately.
→ No test environment
→ No setup
→ No scheduling a demo just to hear how it works
Anyone can experience your agent the moment they open the link.
→ Docs
Terms of Service & Privacy Policy Update
We've updated our Terms of Service and Privacy Policy, and added two new sub-processors. These changes take effect on June 1, 2026.
We've made these updates to keep our terms clear, reflect how the platform works today, and stay current with evolving regulations. Review the full documents below:
→ Terms of Service
→ Privacy Policy
We've also added two new sub-processors — Soniox (speech-to-text) and Ironclad (contract management) — to our infrastructure registry. No action is required; view the full list at our Trust Center.
No action is required to continue using Retell AI. Your continued use of the Services on or after June 1, 2026 means you accept the updated terms.
You can now use ChatGPT to launch production-ready AI voice agents for real phone workflows.
→ Build an agent with the right prompt, tone, language, voice, and call behaviors
→ Deploy to a live phone number
→ Test scenarios with test calls or chats: booking, escalation, voicemail, and more
→ Monitor call performance and iterate over time
Launch your first agent in ChatGPT with the Retell GPT App
When a caller speaks slowly, the agent slows down. When they speak fast or start to respond more eagerly, it speeds up to match. If they ask the agent to change pace, it adjusts immediately.
→ Elderly and hearing-impaired callers get a patient, measured pace
→ Fast-paced callers get snappy responses that respect their time
→ Non-native speakers get an agent that mirrors their rhythm
→ Any caller can say "slow down" or "talk faster" and the agent responds naturally
One agent configuration now handles the pace of every caller, automatically.
Split call traffic by percentage across multiple agents
→ Test a new prompt on 20% of inbound support calls
→ Compare two voices on outbound sales calls
→ See which agent performs best in your call analytics before rolling it out to 100%
Works for inbound and outbound calls. Set agent weights, deploy, and iterate.
Read A/B Testing Docs
Copy, Paste, and Undo Shortcuts: Use Cmd/Ctrl+C, Cmd/Ctrl+V, to copy and paste nodes across CF agents and components, or and Cmd/Ctrl+Z quickly undo changes.
New Node-Level Overrides: Override agent defaults per conversation node with controls for voice speed, responsiveness, and even the LLM.
Node Functions for Conversation Nodes: Add tools/functions to a specific conversation node.
Global Node Cooldown: Prevent a global node from firing again immediately after it triggers by pausing it for a set number of node steps.
Webhook Event Controls: Choose exactly which events each webhook receives, including new transfer events like started, bridged, cancelled, and ended.
Timezone-Based Hour Variables: Use built-in dynamic variables like current_hour_[timezone] to reference the current hour in a specific timezone.
ElevenLabs v3 Voices: Retell now supports ElevenLabs v3 voices, bringing more expressive speech with stronger emotion, cadence, and delivery. A strong fit for teams optimizing for voice quality and realism.
Data Retention Periods: Set how long call and chat data is kept per agent, then have it automatically and permanently deleted when that window expires.
PCAP Downloads for Call Debugging: Download packet capture files from the call details page to troubleshoot network or audio issues with tools like Wireshark.
Deprecation of Phone Number Agent Fields:
On March 31st, Retell will deprecate the old single-agent phone number fields in favor of weighted agent lists for inbound, outbound, and SMS routing.
If you use phone number APIs today: replace fields like inbound_agent_id and outbound_agent_id with inbound_agents, outbound_agents, inbound_sms_agents, and outbound_sms_agents.
No immediate action is required: existing data is converted automatically, and the APIs stay backwards-compatible until 03/31/2026 for single-agent setups.
TTS pricing adjustment:
A reminder that ElevenLabs pricing updates on March 23. Under the new model, ElevenLabs TTS starts at $0.04/min, with pricing varying by model.
We also have powerful alternatives with the introduction of Retell Platform Voices and the existing Minimax, Fish Audio, Cartesia, and OpenAI all at $0.015/min.
You can compare them directly in the playground, see the previous pricing announcement here.
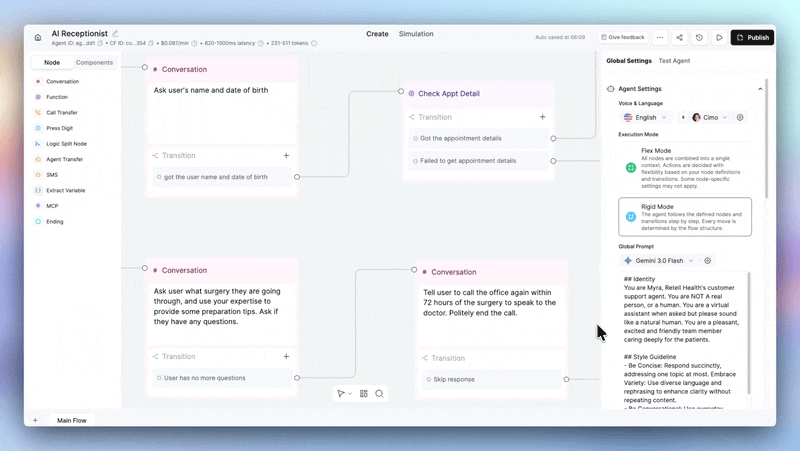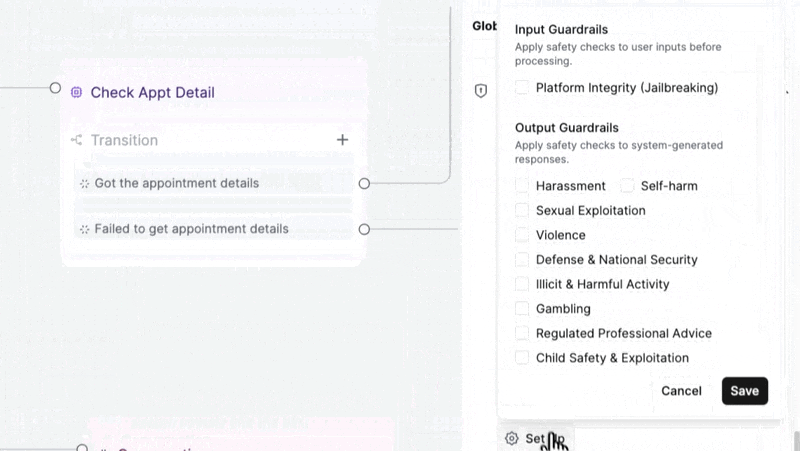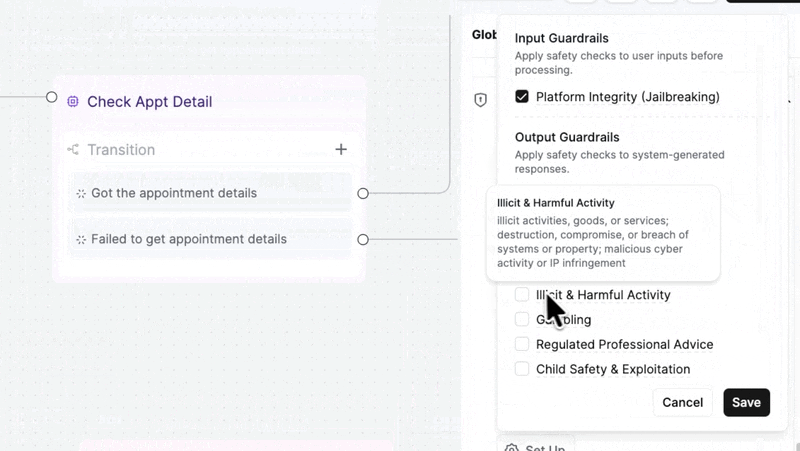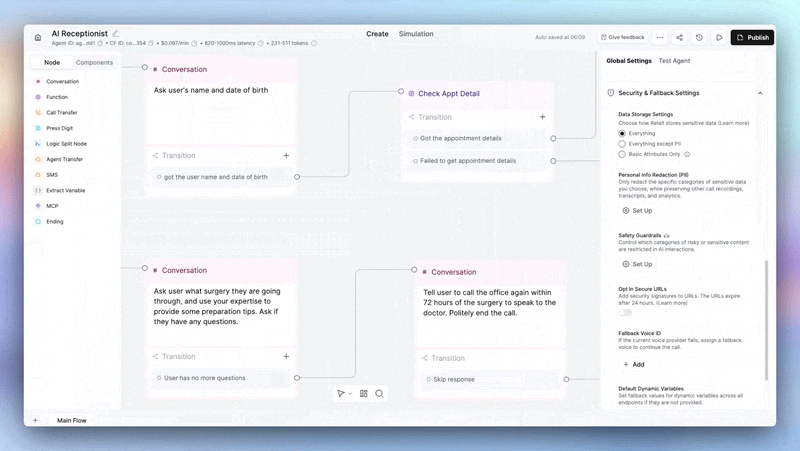
Your agent can now refuse what it shouldn't engage with.
→ Block jailbreaks — prompt extraction, instruction bypasses, unauthorized tool calls. Caught and killed before they reach the caller.
→ Filter harmful output — harassment, self-harm, violence, gambling, regulated advice, sexual exploitation, child safety, and more. You choose which categories are off-limits.
→ Hard stops, not soft warnings — when a guardrail fires, the agent doesn't hedge. It won't produce that content. Period.
Enable per-agent under Security & Fallback in agent settings. Available on all plans.
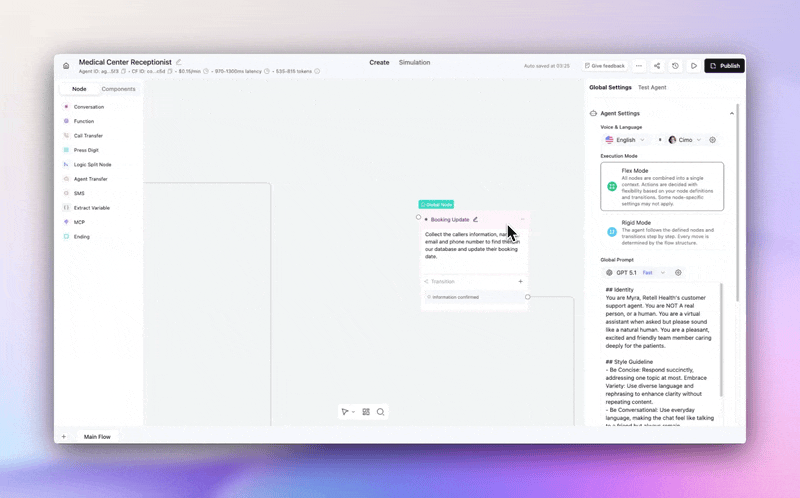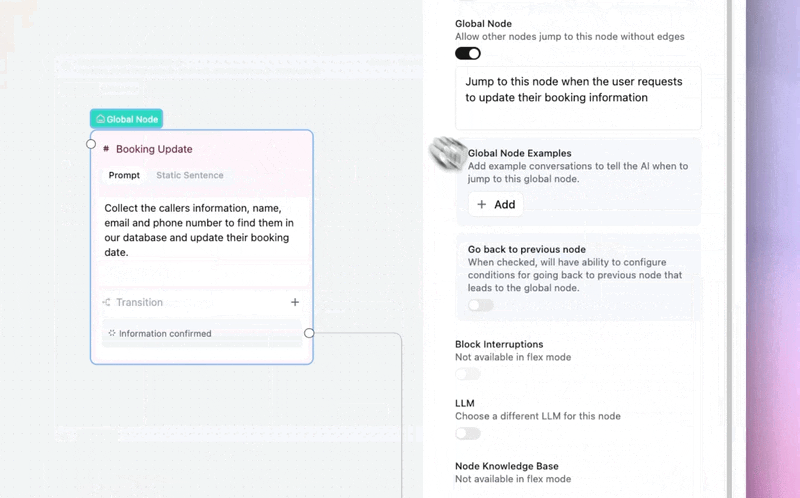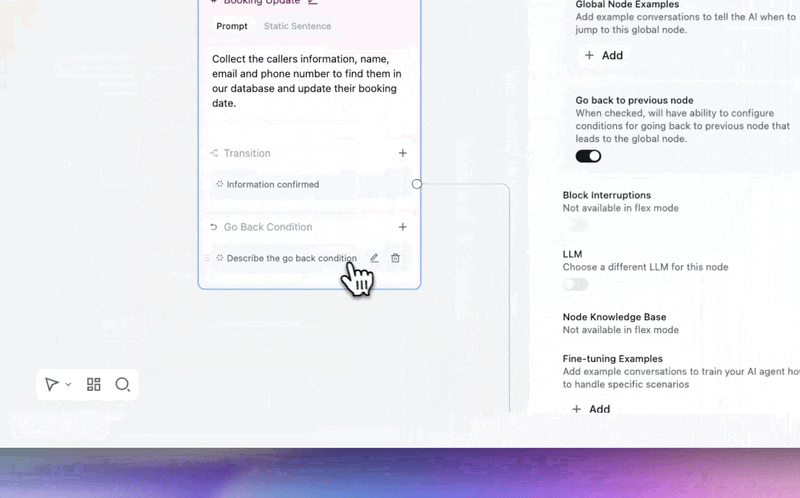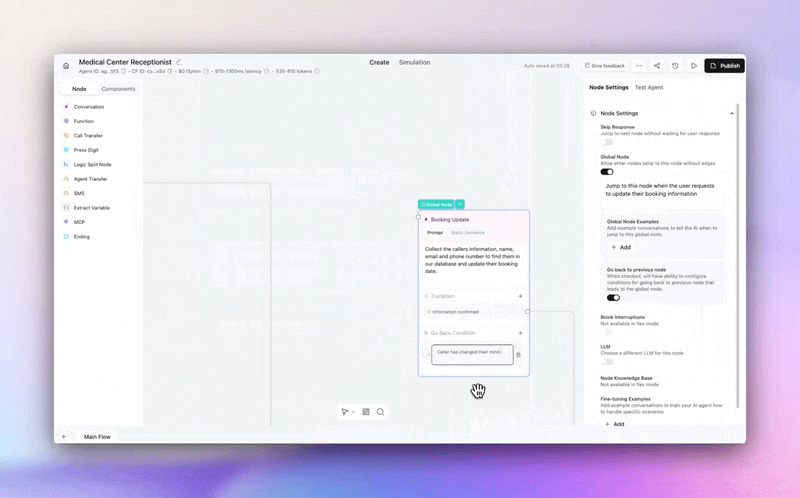
Customers can now leave a global node and come back to exactly where they were in the conversation.
→ No lost progress — a caller asks about your callback policy mid-booking, gets the answer, and picks up right where they left off. No restart, no repeated questions.
→ "Actually, never mind" just works — if a customer triggers a global node then changes their mind, the flow resumes naturally, like a real conversation would.
Enable per-node in any global node's settings.
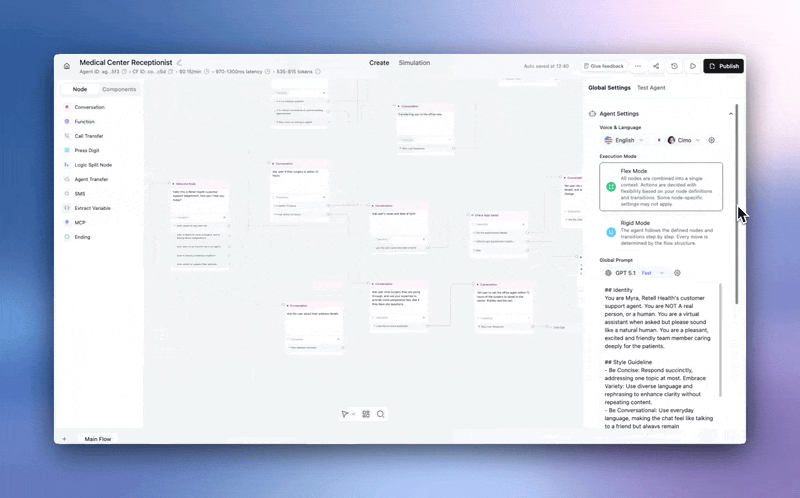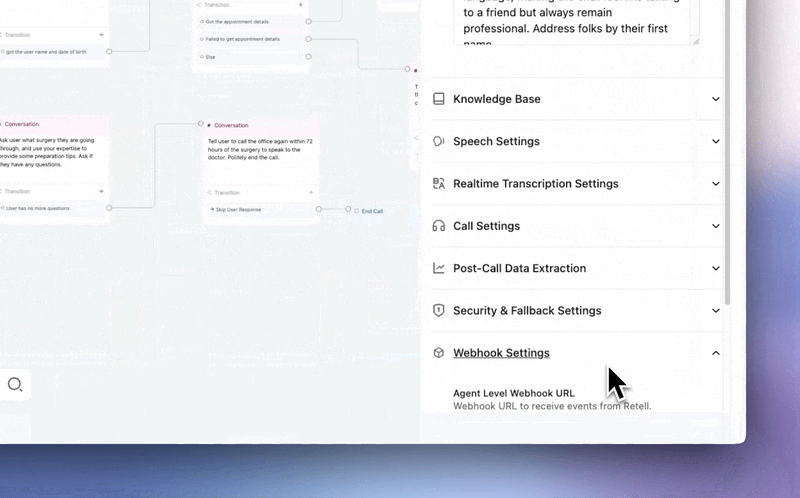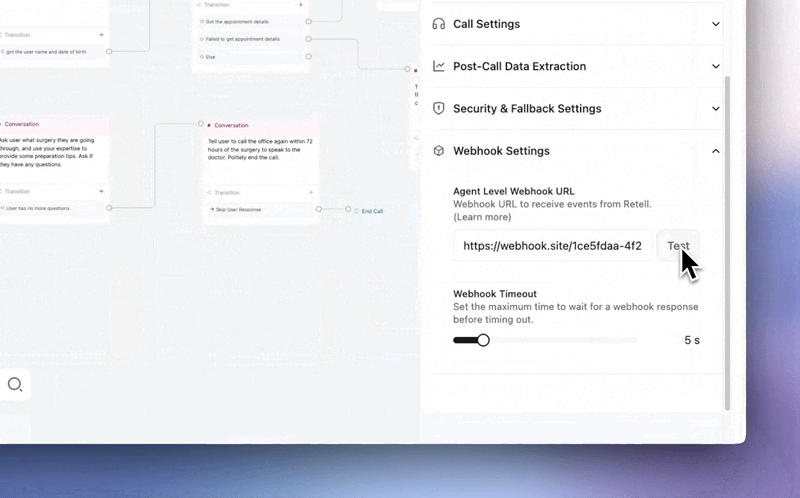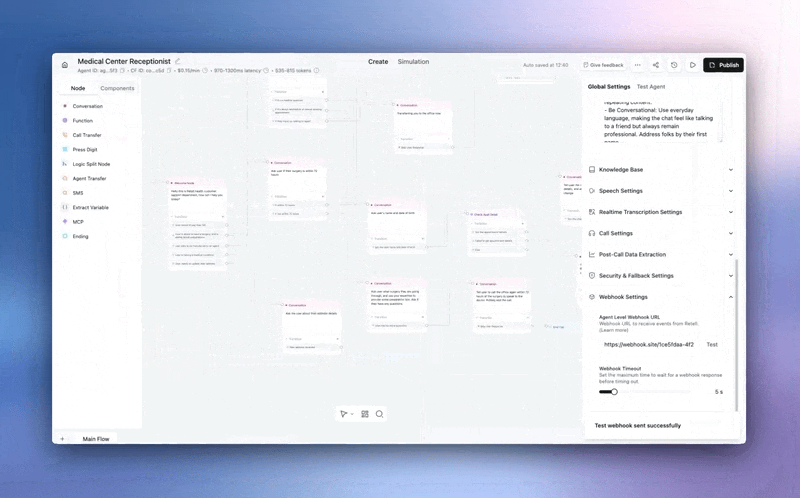
Stop deploying integrations blind.
→ Webhook testing — Hit Test, get a real payload sent to your endpoint. Same structure, same data your agent sends in production. Catch auth failures, bad URLs, and schema mismatches before a single live call.
→ Custom function testing — See variable substitution, test connectivity, preview the response. No live call required.
Available for Agent Webhooks, Alert Webhooks, and Custom Functions.
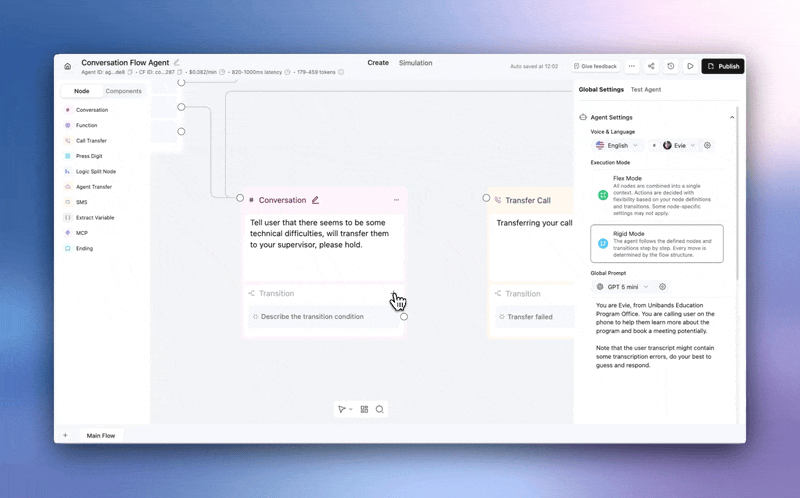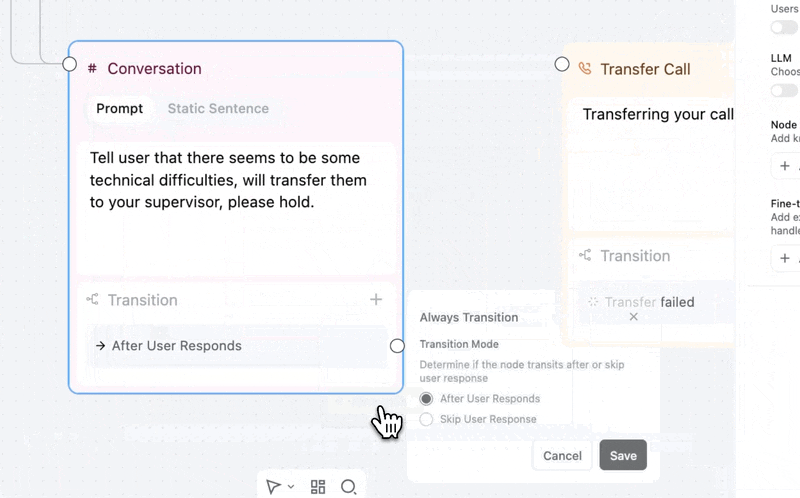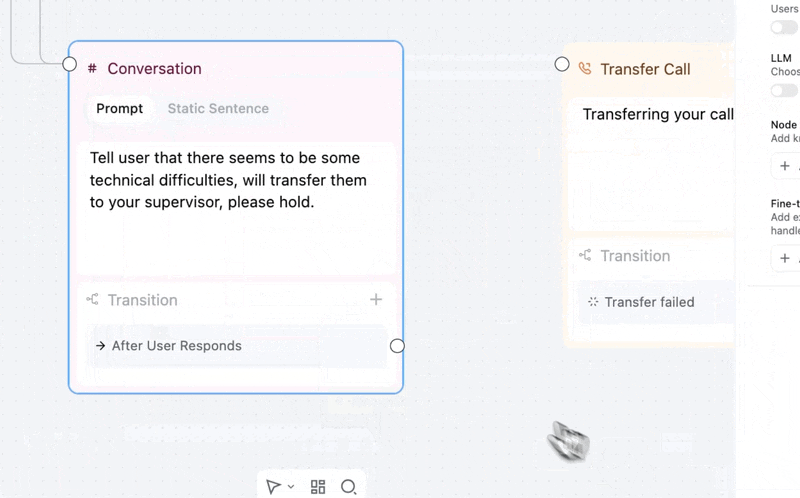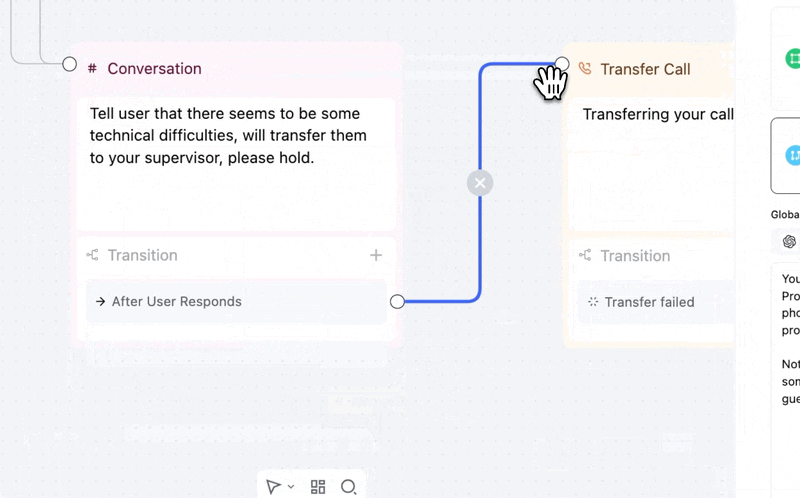
Force any conversation node to move forward, no matter what.
→ Overrides everything — an Always edge that overrides other transitions on that node. One path, guaranteed.
→ You control timing — "After User Responds" waits for input first. "Skip User Response" transitions immediately.
Add via the transition dropdown → Always/Skip, then set your transition mode. This replaces the old skip-response toggle with a more flexible model.
Audio Transcription Auto-Failover — Deepgram goes down? We switch to Azure. Azure goes down? We switch to Deepgram. Mid-call. No audio dropped.
Batch Testing API — Define test cases, run them in bulk, get results back — all via API.
Branded Caller ID (Custom Telephony) — Show your company name on outbound calls and reduce spam flags. Now works with your own telephony numbers, not just Retell-managed. U.S. only. Requires business profile.
Advanced Call & Chat Filtering — Filter by custom analysis data and dynamic variables. Pin specific agent versions to pull from.
TTS & Voice Engine — Now Separate Line Items
Your invoice previously bundled TTS and voice engine costs together. They're now broken out — you can see exactly what each costs across voice engines, LLMs, and telephony.
Concurrency — Billed Upfront, Prorated by Day
Concurrency is now charged when you add it, not at the end of the month. Add capacity mid-cycle and pay only for the remaining days.
Seven deprecated models have been automatically replaced. If your agents used any of these, they're already running the new versions:
GPT-4.1 is not being deprecated on Retell. OpenAI recently removed it from ChatGPT. We've seen some of you asking about this — GPT-4.1 is staying on Retell. Your agents running it continue to work as-is.
We're thrilled to share some exciting new features and updates on the platform. Here’s what’s new:

AI QA automatically reviews your calls and provides crucial feedback 24/7.
With AI QA, you can:
→ Surfaces patterns in your calls: Find and fix systematic issues without getting stuck on one-off bad calls.
→ Track Resolution rates across every call: Transfer rate, disconnect reasons, repeat contact patterns — by agent, call type, time period.
→ Catch what humans can't: Hallucination rate, sentiment shifts, tool accuracy — measured automatically across every call.
First 100 minutes of analysis is free.

With Alerting you can set triggers that alert you the moment something goes wrong with your agents.
Alerting lets you:
→ Know when an agent burns $100 in minutes, success rate hits 0%, sentiment drops 20% and more.
→ Delivered via email or integrate into your existing tools via webhook
→ Smart thresholds so you only get alerted when it actually matters
It only takes 2 minutes to set up your first alert.
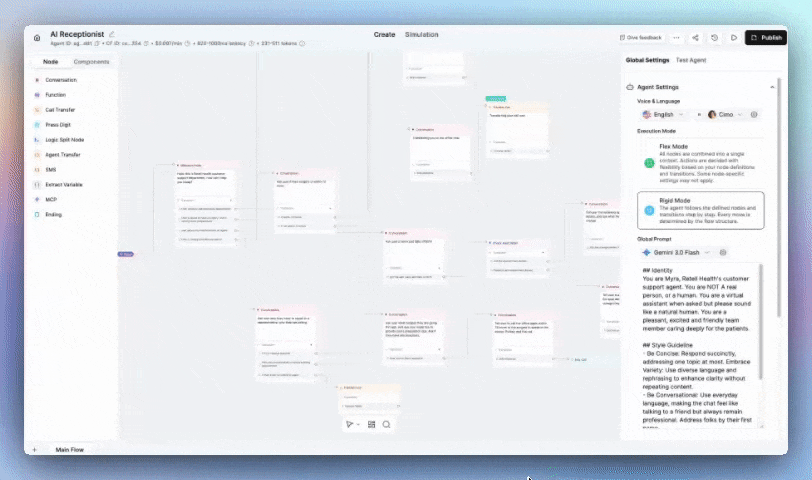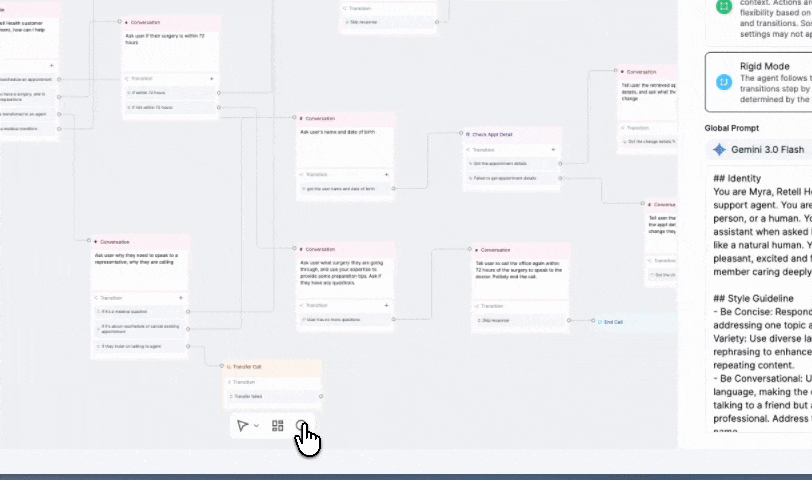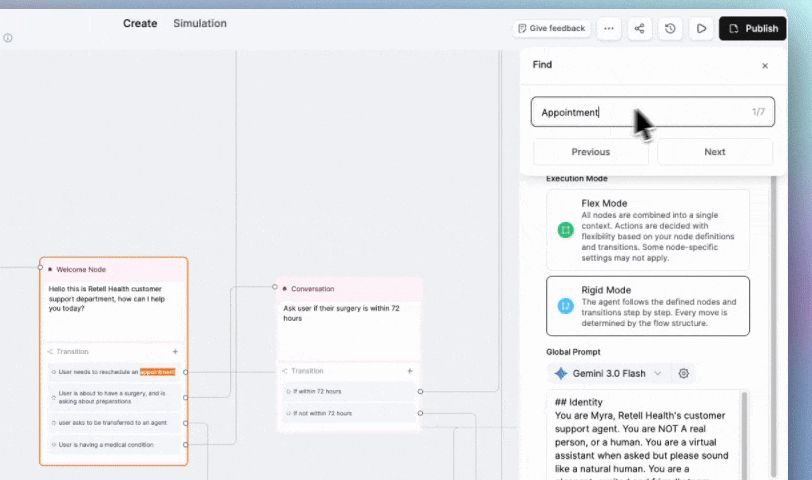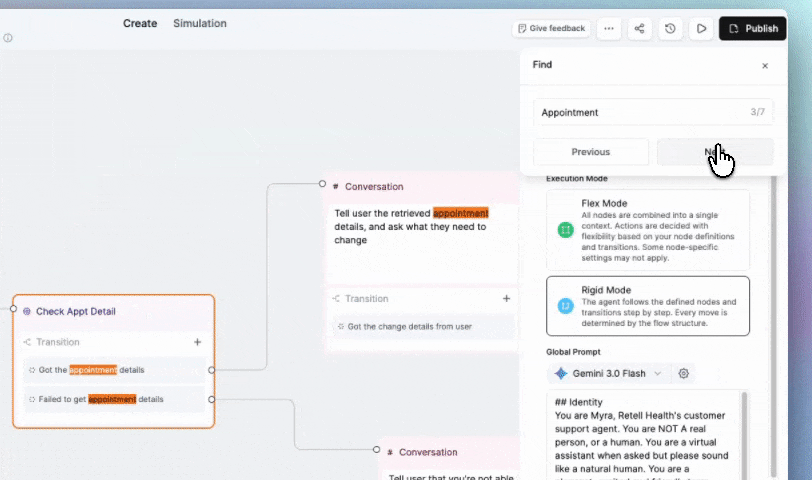
Search between any node in seconds using the search box or cmd/cntrl+F to review and audit large flows faster.
Export Call History — Export any of your agents' entire call history with URL's.
Voice API — Add-voice, search-voice, and clone-voice APIs are now exposed through the SDK.
Custom Transcription Config - You can now choose between optimizing for accuracy or latency by changing the number of endpoints used
HubSpot Integration — Retell is now available through the HubSpot Marketplace.
Auto IVR Hangup — You now have an option to automatically hang up if your agent encounters an IVR system.
Auto transcription fallback — If Deepgram or Azure has an outage, we seamlessly switch to the other provider without dropping audio, even mid-call.
Voice Emotion Control — Cartesia Sonic-3 models now support Happy, Surprised, Sympathetic, and Calm. MiniMax voice models now support Happy, Surprised, and Calm
Concurrency Blast — Allows up to the lower of 3x your concurrency limit or 300 additional concurrent calls. $0.1/minute for burst usage.
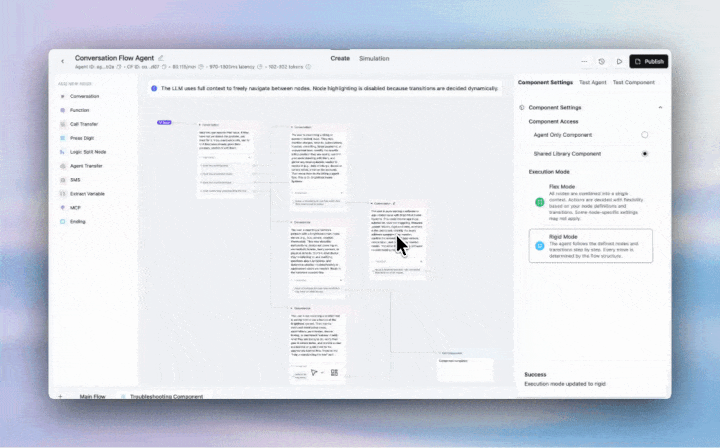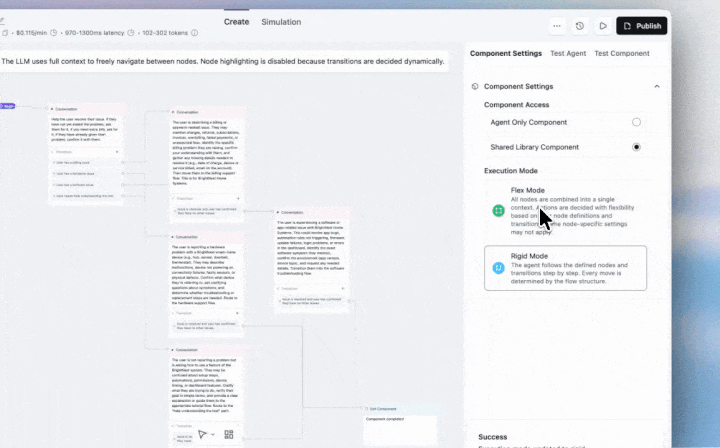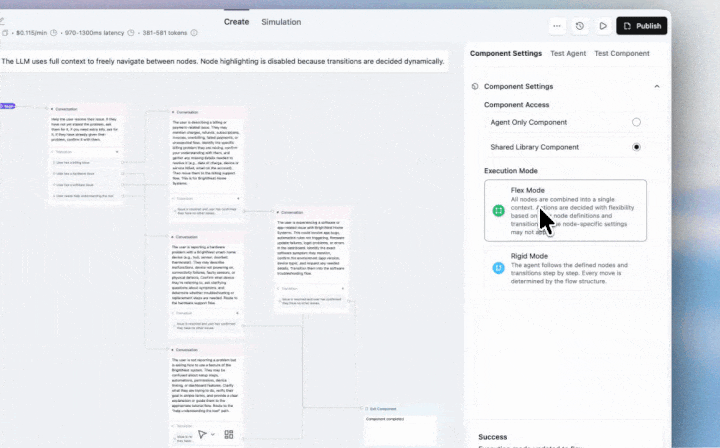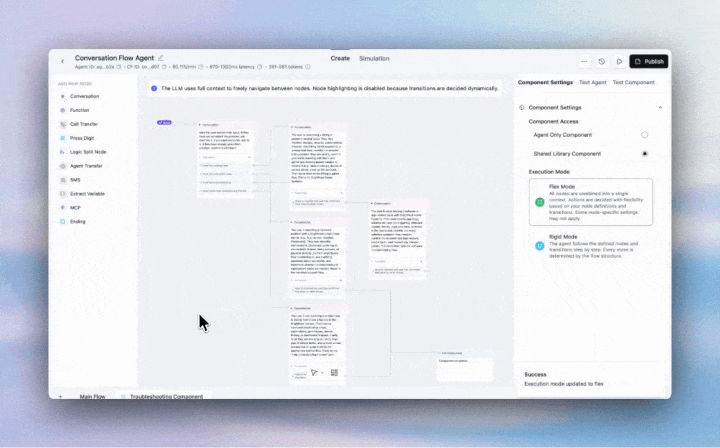
Flex Mode lets your agents navigate flexibly between nodes as customers jump between topics, have multiple requests, or change direction mid-call.
With the introduction of Flex Mode, you can:
Perfect for complex support flows, multi-service requests, and any conversation where customers have multiple/varied requests in a single call.
Enable at Agent or Component level. Best for flows under 20 nodes.

Advanced Warm Transfer adds a live AI handoff assistant that lets your human agents engage with the AI before accepting or declining a call.
With Advanced Warm Transfer, you can:
The handoff assistant is fully configurable - build simple briefings or complex multi-step workflows with function calls, and more
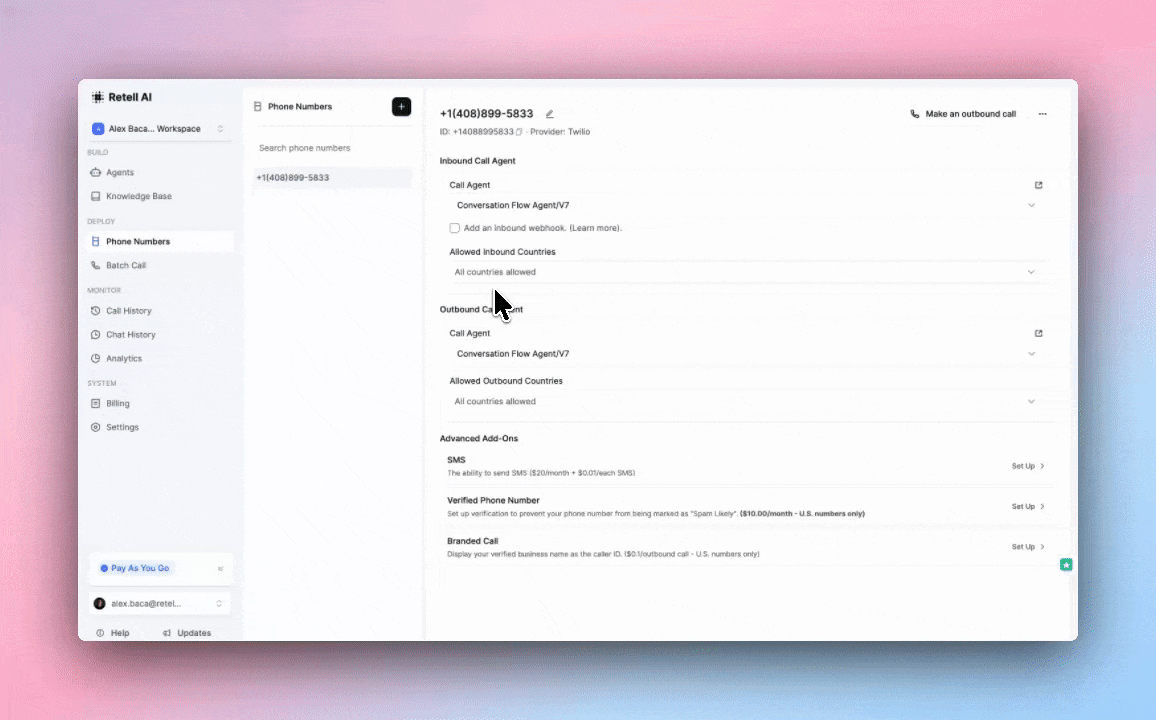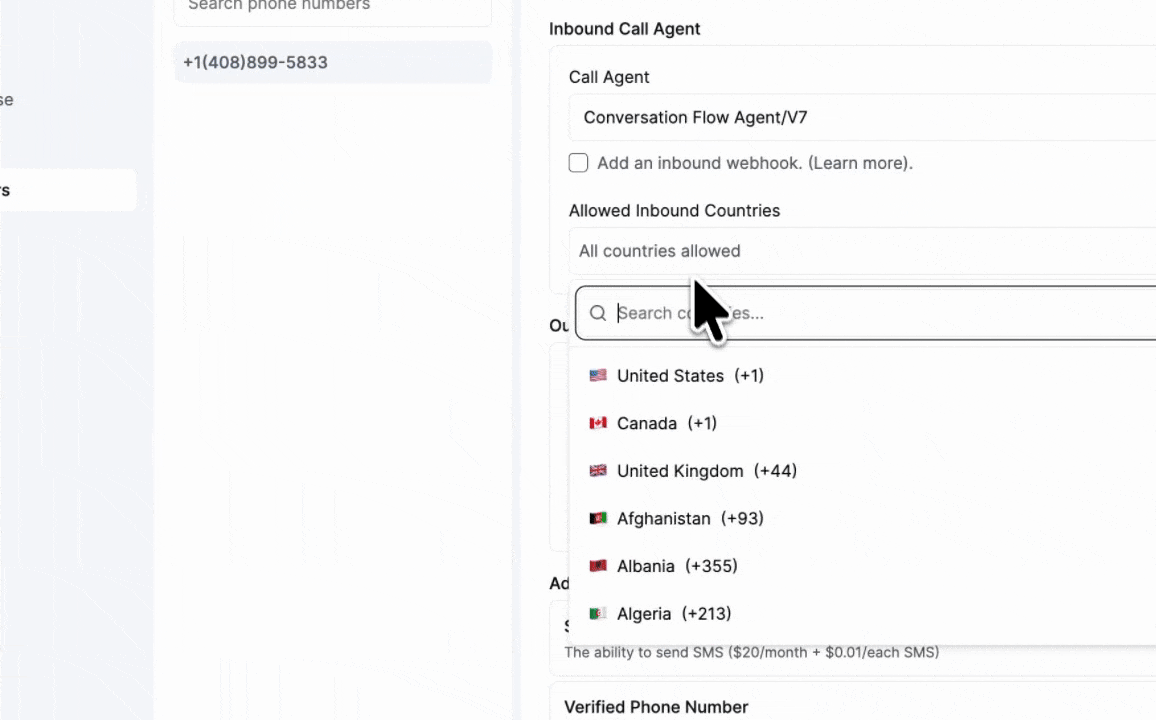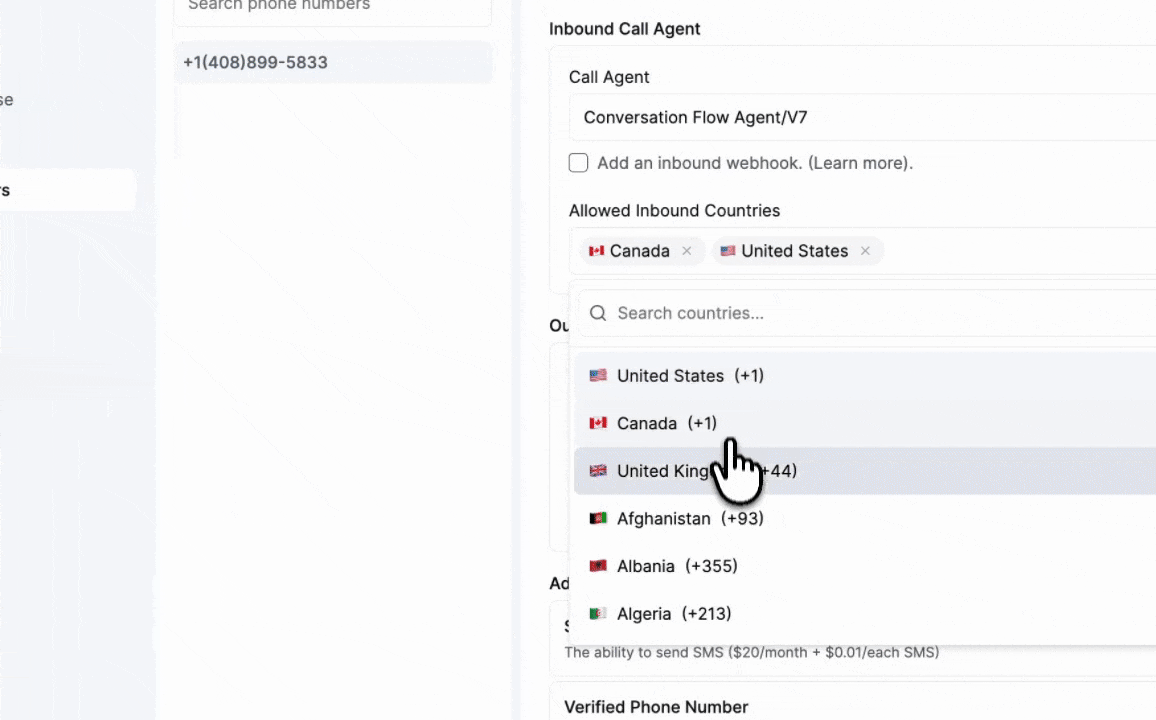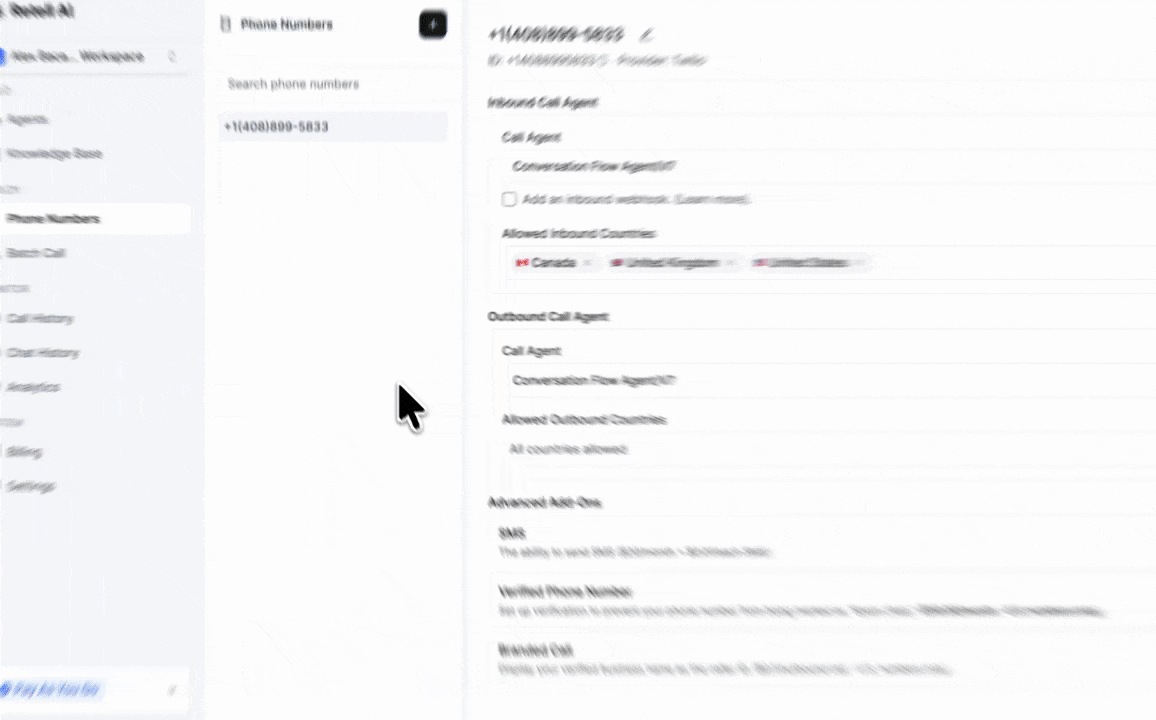
Country Restrictions are now available on all numbers. — Block inbound and outbound calls to countries you don't want connecting with your agent.
Agent Version Comparison — Compare any two agent versions with semantic diff. View changes side-by-side, with difference-level highlighting.
Rerun Post-Call Analysis — Modify analysis prompts and regenerate summaries across historical calls without re-running the calls.
Per-Call Agent Override — Dynamically override agent configuration at the call level for both inbound and outbound calls.
Concurrency Dashboard — Monitor active call concurrency over the past 24 hours directly in Analytics.
Custom Function Constants — Define fixed parameters in custom functions using static values or dynamic variables.
Chat Agent SDK — Full chat agent API support now available in the SDK.
Phone Number Editing — Modify custom telephony and Retell numbers directly from the dashboard.
New Models: GPT-5.2, Gemini 3 Flash, Claude 4.5 Haiku & Sonnet
New voices & voice providers:
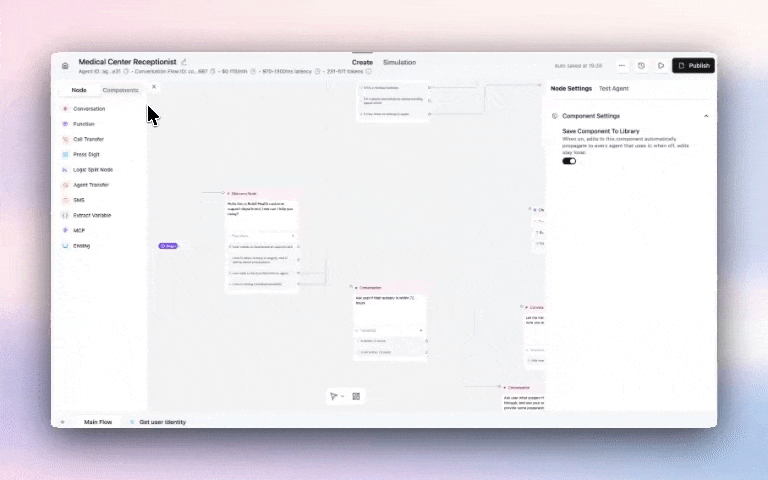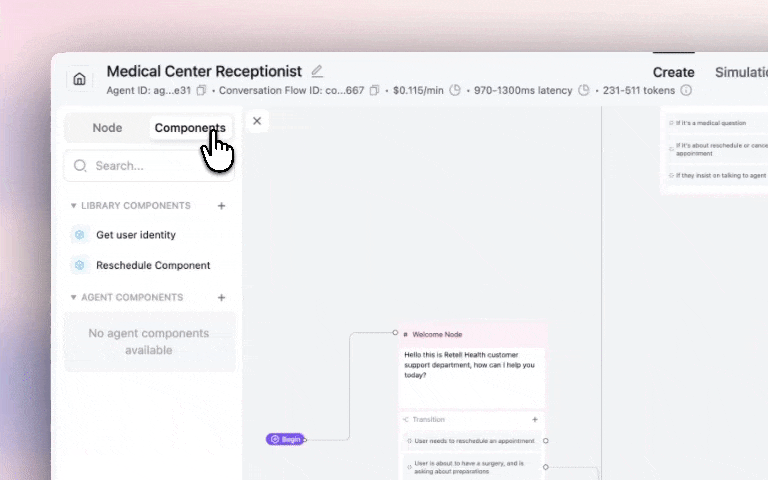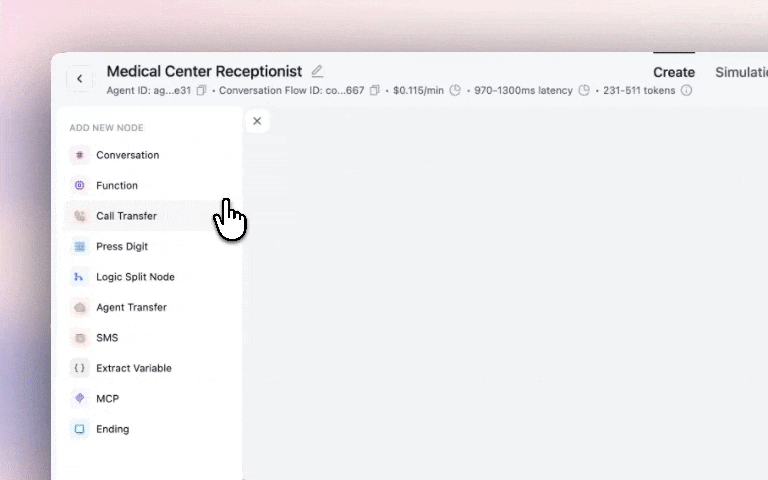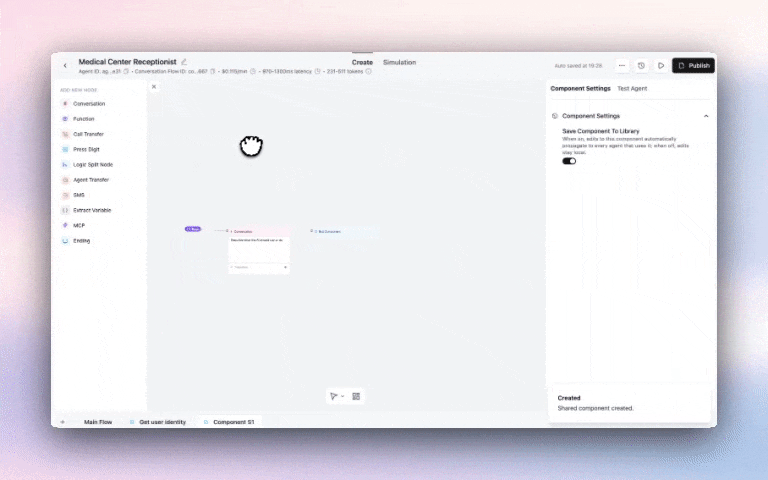
Build reusable sub-flows and functions to keep your agents maintainable and consistent across your entire account with our new Update the component once, and it syncs with all other agents that use it.
Example use cases:
Get started: Agent Builder → Components Tab → + Create → Build your component flow
Join the conversation on LinkedIn
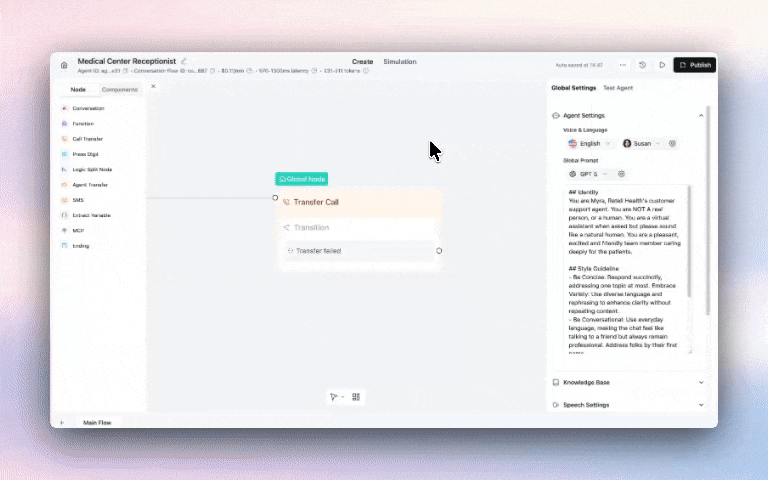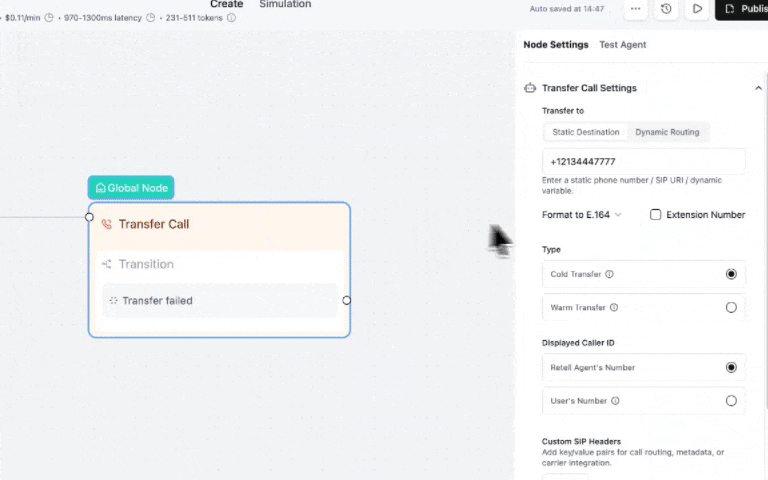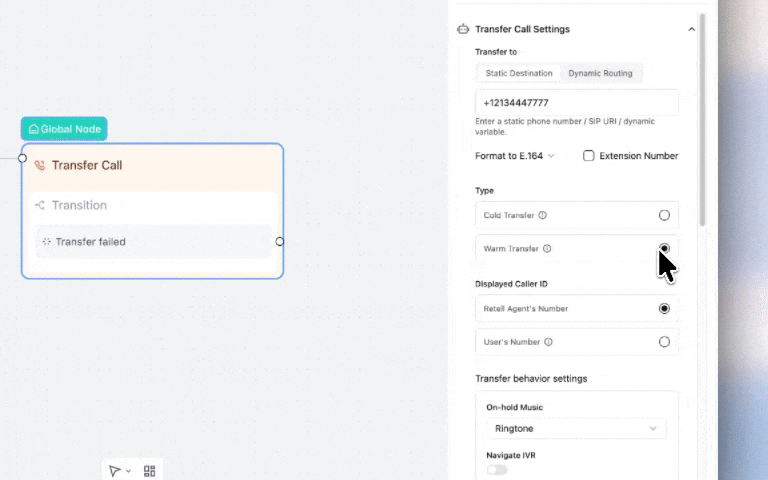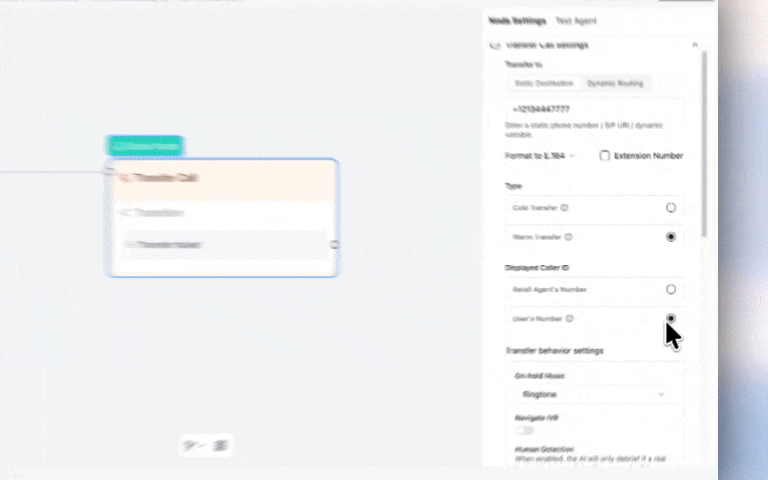
You can now control which caller ID appears when transferring calls, warm and cold — showing either your AI agent's number or the original caller's number.
Why this matters:
When your sales or support team sees the real caller's number, they can pull up CRM records instantly before picking up and call customers back if the call drops. Critical for lead qualification workflows and HIPAA-compliant healthcare operations where caller tracking is required.
Set it up: Call Transfer Node → Caller ID Settings → Select "User's Number"
Join the conversation on LinkedIn
You can now add custom fields to track exactly what matters for your business and reorder your Call History columns to match your workflow.
Set it up: Call History → Customize View → Add Custom Attribute / Drag to Reorder
The following LLM models have been deprecated. Please update your agents to the latest models.
Additionally, start_speaker is now also required in the create-retell-llm API.
Previously, knowledge bases could only be set globally. With Node KB, you can now assign a specific knowledge base to a specific node in your conversation flow.
This update allows agents to:
Start Using Node KB Today
Until now, any team member could change critical settings. With the new Role-Based User Manager, you can assign access levels across your team:
This makes it possible to:
👇 Assign roles today in the User Manager.
To protect against toll fraud and spam, we’ve added Google reCAPTCHA to Retell’s Public API keys, chat, and call widgets.
This makes your account:
✨ How it works
Your agents can now send Outbound SMS directly to customers, not just reply when contacted.
With this release, agents can:
👇 Get started with Outbound SMS
Your Retell AI agents can now automatically navigate IVR menus using DTMF (digit-press) inputs — no more waiting around or manual instructions needed.
With this update, agents can:
Try it now with the Press Digit function in your workflow
Until now, batch calls could only be launched immediately or scheduled at a single time. With Batch Call Window, you can now define exactly when calls are allowed to run — setting specific hours and days of the week.
👉 Start using Batch Call Window today to keep your campaigns on-time, efficient, and compliant.
Retell Telnyx phone number call rate will be adjusted from $0.015/min to $0.020/min.
This update will take effect starting September 1st.
Twilio phone number pricing will remain the same, with no changes to the current rate.
We’ve added the latest GPT-5 family to Retell:
💡 Our testing shows GPT-5s handle transitions well but can be verbose in replies. Try them out and share feedback!
You can now connect chat agents to SMS using either a Retell Twilio number or your own Twilio setup.
With 2-Way SMS, you can:
How to get started:
Retell SMS A2P Application Ultra Guide
Security and compliance are critical in every call.
Retell now can detects and removes sensitive data (names, addresses, DOBs, passwords, PINs) from both transcripts and recordings.
Pricing: $0.01/min add-on

✨ How it works
Previously, international calling was only possible through custom telephony setups. Now, native Retell numbers support international calls to 14 countries, so you are no longer limited to the U.S.
Protect deliverability and avoid carrier throttling by setting Calls-Per-Second caps per provider.
Per-provider control means you can balance load intelligently across Telnyx, Twilio, and your custom stack. The result is steadier throughput and fewer failed attempts.
You now control webhook timeouts for both workspace-level and agent-level webhooks (default 5s)
Give longer-running tasks room to complete, or force fast failures when you prefer to fall back and retry.
Now you will experience:

You can now seamlessly switch between Retell agents during a call, no more clunky transfer workarounds using phone numbers.
This unlocks a powerful way to design modular, reusable agents for specific tasks, like:
🔹 Language routing agent
🔹 CSAT survey agent
🔹 Payment agent
These agents can be inserted anywhere in your call flow, and when transferred, they inherit the full context of the original conversation.
You can now connect your own MCPs and invoke tools seamlessly.
With Retell AI’s MCP Node, your voice agents can:
- Call any HTTP-based service (Zapier, custom APIs, CRMs)
- Trigger workflows and fetch live data in real time
- Dynamically adapt the conversation based on structured responses
- Stay secure with scoped access, headers, and timeouts
The feature you’ve been waiting for is here! Static IP addresses are now available for U.S. calls, giving you complete control over your telephony set up . This is perfect for enterprise integrations and custom call routing.
The Conversation Flow API is finally here in our SDK!
Create and manage conversation flows programmatically, bringing unprecedented automation and flexibility to your workflows. Plus, get API access to MCP, Warm Transfer, and Agent Swap all in one update!
You can now transfer calls directly to a SIP URI for both cold and warm transfers
Integrate with any SIP-compatible system effortlessly and expand your telephony possibilities!
Chat History is now live!
Full chat history tracking is now available, giving you complete visibility into all your AI interactions for better insights and follow-ups.
Our Knowledge Base just got a major upgrade, and your AI agents are now a whole lot smarter:
- Smarter recall: Agents now focus on the most relevant parts of each conversation to retrieve accurate answers.
- Improved ranking: Irrelevant chunks no longer show up ahead of the correct information.
- Better precision: Key details like phone numbers and addresses are much more likely to surface, even when earlier conversation turns introduce unrelated context.
In large-scale tests across multiple use cases, KB 2.0 achieved:
📈 Up to 50% improvement in answer accuracy
🔍 More relevant top-ranked results
🧠 Clearer answers to complex, multi-turn questions
We’ve rolled out major improvements to warm transfers to give you more control and clarity during call handoffs:
Links to documentations: transfer call function, transfer call node
You can now turn post-call analytics into visual charts. Such as appointment booking rate, interest level, or lead score.
📊 Add a new chart
🎯 Select an agent, choose post call analytics metrics
🎨 Choose a chart: column, bar, donut, or line

Your agents can now extract and store dynamic variables live and mid-conversation, with reliably and accurately retrieved information.
Your agents can now:
Variable Types You Can Collect:
Work in both single, multi and conversation flow agent.
We’ve partnered with Cartesia to bring your agents a lifelike, ultra-smooth voice experience.
You can now set Cartesia as your default voice, or use it as an automatic fallback if your primary provider goes down.
You can now add example conversations for AI to know when and when not to jump to Global Nodes in your agent’s conversation flow.
Start using by enabling the Global Node option on any node in the conversation flow builder.
You can now enable auto-add future pages for specific URL paths.
Once enabled, any new pages added under those paths will be automatically detected, crawled, and kept up to date.
For example, if you specify a domain like docs.retellai.com, any new pages added under that domain will be auto-crawled going forward.
You can now embed a Retell Chat agent directly into your website or app — enabling users to interact with your AI agents via a modern, lightweight text UI, without any setup overhead.
How to set it up:
1. Copy and paste the embed script into your website
2. Replace the publicKey, agentId, and version
3. Customize widget name

Copy paste the embed code to add your chat agent— no backend work required.
Unlike API keys, which must remain private, Public Keys are designed for frontend use and are required for authorizing access to the new chat widget.
Manage your keys here:
Dashboard → Keys → Public Keys
You can now use Custom Functions to:
The former “High Priority” model option is now Fast Tier, with upgraded performance and a reduced price:
• Predictable latency
• Uncapped scale
• Higher reliability
• New pricing: 1.5x model cost (down from 2x)
To give you better visibility into failed calls, we’ve expanded the list of disconnection reasons and restructured the call status reporting for outbound dials.
New disconnection_reason values:
🗓 Effective Date: June 30, 2025
Ensure your integration handles these new values properly.
We’ve launched a medical vocabulary setting for English voice agents. When enabled, transcription will favor terminology commonly used in clinical and healthcare scenarios — improving accuracy for patient-facing use cases.
Currently available for English agents only.
We’re making a few changes to our pricing model to better align with usage patterns and infrastructure costs. These updates will go into effect on June 1st:
Latency and stability have always been core priorities at Retell. By leveraging the latest LLMs, we’re not only benefiting from improved performance and lower costs, but also applying smarter strategies to keep the platform fast, consistent, and reliable.
We’ve recently made additional optimizations to reduce latency and improve stability:
Learn more about the other strategies how we maintain 99.99% uptime.
We’ve released the SMS feature!
You can now register the SMS function using your Retell number and send SMS messages during a call. Simply add a function node in your conversation flow or use it within a single or multi-prompt.
More tutorials coming soon!
We’ve enhanced our keypad input feature to better support different data collection scenarios. You can now choose from multiple input-ending methods:
These options make it easier to customize voice agent behavior to fit your exact workflow.

Denoising Mode Just Got Updated
You can now choose between two levels of noise cancellation:
Perfect for boosting transcription accuracy in noisy environments.

Equation-Based Transition for Conversation Flow is now live.
If you gather information during the conversation, simply select {{dynamic variable}} = value or string = value in your equation to help the LLM understand and route properly.

Retell MCP Server now live:
Connect your favorite AI assistant (ChatGPT, Claude, Cursor, Grok, etc.) directly to Retell’s voice agent platform:

The GPT-4.1 family is now live on Retell AI! Here’s how the models compare:
Intelligence:
GPT 4.1 > GPT 4o mini > GPT 4o > GPT 4.1 mini > GPT 4.1 nano
Latency (lower is faster):
GPT 4.1 nano < GPT 4.1 mini < GPT 4o mini < GPT 4o < GPT 4.1
Price (per minute):
GPT-4.1 nano ($0.004) < GPT-4o mini ($0.006) < GPT-4.1 mini ($0.016) < GPT-4.1 ($0.045) < GPT-4o ($0.050)

You can now create and manage agent versions directly in the Agent Builder:
• Make changes and test your agent safely—without affecting your live production calls.
• Revert to any previous version with a single click.
Just hit the “Deployment” button to save a version, and use the history button to view and restore previous versions.

You can now enter dynamic variables when sending a test call directly from the platform—making it easier to simulate real scenarios during testing.
Note: The test call will automatically pull in the dynamic variables you’ve set in the agent configuration.
Multilingual has updated!
Now support seamlessly switching between English, Spanish, French, German, Hindi, Russian, Portuguese, Japanese, Italian, Dutch.
(using nova 3)

We’ve also added support for 10 more languages:
Romanian, Danish, Finnish, Greek, Indonesian, Norwegian, Slovak, Swedish, Bulgarian, Hungarian.

If you want to prevent unauthorized access in case the URL is leaked, you can opt in for secure URLs. Secure URLs automatically expire 24 hours after they are generated, providing an additional layer of security.

We’ve launched Simulation Testing for both single and multi-prompt agents!
Now, instead of manually typing inputs, you can write a user prompt to quickly simulate a full conversation.
We’ve also added Batch Simulation Testing, so you can run multiple test cases at once with ease.

More system default dynamic variables, currently support:
For Phone calls only:

Add a default value for dynamic variables across all endpoints if they are not provided.

If you want to use different agents under the same inbound phone number, such as setup a daytime agent and a afterhour agent, or route to different agent based on the incoming phone number.
This is now possible with the Phone Inbound Webhook.

We’ve added more LLM options for post-call analysis.
If you find the default analysis isn’t accurate, feel free to switch to GPT-4o.
Once selected, GPT-4o will be charged at $0.017 per session.
If you choose GPT-4o Mini, post-call analysis remains free.

To better manage demo and production agents, you can now organize them using folders.
If you prefer not to use this feature, simply collapse the folder view.
Now you can use our analytics dashboard to monitor the performance of Voice AI Agents:
• Monitor key metrics like call success rate, transfer rate, call counts, and latency variations...etc
• Compare A/B test results across different agents.
• Create custom charts tailored to your needs.
• Easily dive deep into programmatic calls for better troubleshooting.
This feature will be available for free starting early next week!
We’ve released an advanced testing suite with a bunch of exciting features:
1️⃣ Debug AI responses and regenerate them as needed.
2️⃣ Simulation testing without manually typing input.
3️⃣ Batch simulation testing, allowing you to run multiple test cases at once.
We also started charging for the Test LLM feature on March, 1st.
Coming Soon: Support for Single Prompt and Multi-Prompt testing.
You can now purchase Telnyx phone numbers directly on our platform.
Due to recent restrictions on Retell’s Twilio numbers, we’ve implemented a manual fallback. If you need a specific local number, you can purchase a Telnyx number for seamless outbound calling.
You can now export and import any agent to your different organizations.

Export the complete call history using the selected filters and column settings, mirroring the call history table.
1. New Voices for OpenAI Realtime: openai-Ash, openai-Coral, openai-Sage
2. LLM and TTS Fallback for individual calls
3. LLM deprecation & upgrade:
We will deprecate the V1 APIs and certain deprecated fields in webhooks on February 5, 2025.
Below is a summary of what will be deprecated:
To avoid disruptions, please complete your migration before the deadline.
See Docs
AI phone agents can sometimes struggle with capturing long numbers accurately due to background noise or unclear speech. Our new Listen to User Keypad Input feature allows callers to enter numbers using their keypad, improving accuracy.
How It Works:

Listen to user keypad input | Capture DTMF input from userSee Docs

Need to route calls based on different customer requests? Try Dynamic Routing in call transfers.
Example:
Set up call transfer logic to automatically direct calls to the right department.
- Customize how long the phone rings before a call is answered.
A new API for batch calls is now available.

For compliance reasons, you can now delete call records completely or removing only recording and call transcription.
.avif)
To better understand our customers, we’ve introduced a new questionnaire for all users, including existing ones.
Please take a minute to fill it out—it will be available on our dashboard today.

We’ve launched the beta version of our Conversation Flow!
This new tool provides much finer control over conversation flows compared to single or multi-prompt agents, unlocking the ability to handle more complex scenarios with ease.
Key Features:
Highlights:
Get started with a pre-built template today and share your feedback with us!

We received fantastic feedback from the last session, and we’re excited to bring even more value this time. If it’s not already on your calendar, make sure to save the date!
What to expect:
1️⃣ Live troubleshooting for Retell voice bots
2️⃣ Integration help for your projects
3️⃣ Best practices and advanced use cases
4️⃣ Networking with fellow bot builders
5️⃣ Sharing successful case studies
🕒 Time: Friday, 2 PM Pacific Time
📍 Location: Our Discord Channel: https://discord.com/invite/DTzvrQfncB
1. Ringtone when having warm transfer.
• A ringtone is now available during warm transfers for a smoother experience.
Note: For cold transfers with the option to show the transferee’s number, there is currently no ringtone. This issue will be resolved within 1 week.
2. DTMF from user now can show in transcript
• User-entered DTMF inputs are now captured and included in the call transcript for improved usability.

We’re excited to announce the following pricing updates:
1. Significant Price Reduction for GPT-4o Realtime: The price has been reduced from $1.50/min to $0.50/min, making it more accessible for your needs.
2. New Model Introduction: We’ve launched GPT-4o Mini Realtime, available at an affordable rate of $0.125/min.
These changes took effect on December 19th.
Additionally, we’ve updated our telephony pricing to better reflect Twilio’s actual costs. The previous price of $0.01 per minute will be adjusted to $0.015 per minute, effective January.
Thank you for your continued support as we make these updates to enhance our offerings and maintain service quality.

We’ve added ElevenLabs's newest model: Flash v2.5 & Flash v2.
You can switch to this model when you hope to have blazing fast latency.
The differences between the model:
The Flash v2.5 is multilingual. faster but medium quality.
The Flash v2 is English only. faster but medium quality.
The Turbo V2 is high quality with medium fast.

We’ve integrated a new voice provider: PlayHT!
Some Retell voices now have versions available in both ElevenLabs and PlayHT.
You can seamlessly set one as a fallback voice for the other. Enjoy a reliable voice experiences!
Pricing:
Voice engine - Playht $0.08/min

We’ve introduced a feature that adds a pause before the AI initiates speaking during a call. This resolves the issue where the AI starts speaking before the user has had a chance to bring the phone to their ear.
Feel free to try it out if you encounter similar situations.

You can now view Knowledge Base retrieval trunks directly within the Test LLM feature.
This update provides greater visibility into how the Knowledge Base is being used.
Easily check if questions are retrieving the correct information and make adjustments as needed.

Batch Calling is now live! This feature allows you to make multiple calls simultaneously by simply uploading an Excel sheet.
Here’s how it works:
Batch Calling queues your calls without hitting concurrency limits, ensuring a seamless experience.
Pricing: $0.005 per dial (20k calls for $100)

We’ve completely overhauled our documentation to make it more user-friendly and comprehensive. We’ll continue updating it regularly based on your needs.
Have suggestions? Join us on Retell Discord and share your thoughts.
Want to find the answer more easily, feel free to join Retell Discord and ask questions in #AI Evy Channel.
We’ve added TTS (Text-to-Speech) latency details in call history and the Get-call API.
If you notice higher-than-usual TTS latency, switch to another TTS provider directly. (Please note that older latency fields are now deprecated.)

We’ve added the Branded Call feature!
Now, you can enable branded call functionality on each of your phone numbers. It’s a great way to build trust with your outbound calls and significantly improve conversion rates.

Once activated, the recipient will see your business name when you call.

You can now monitor your call records more effectively with these powerful new filters!
For examples:

A detailed dashboard now shows your daily call costs and costs by provider.
Easily track your spending at a glance.

You can now purchase them directly on the dashboard.

Additionally, you can see your live concurrent call usage in the bottom-left corner of the dashboard.

You can now access the Knowledge Base via API.

If you are using OpenAI’s LLM, we’ve added a Structured Output setting.
When enabled, it ensures responses follow your provided JSON Schema.
Note: This feature may increase the time required to save or update functions.

We’ve integrated Claude 3.5 Haiku with a pricing of $0.02/min.

You can now equip your Voice AI agents with your company’s knowledge in three simple ways:
For the "Scrape from Webpages" method, you can select auto-sync every 24 hours or manually sync anytime. No more manual updates!
Pricing for Knowledge Base:

A must-have for outbound campaigns.
If your calls are being marked as spam or blocked by carriers, this verification process will prevent that from happening.
Simply submit your business profile, and after review, if your business is legitimate, you're good to go!

We’ve added the OpenAI Realtime API to our platform. The average latency is 600-1000ms, but pricing is currently $1.5/minute. We expect the pricing will go down soon.

If you're using the call transfer feature and want the next agent to receive the caller’s number (instead of the Retell number), adjust the settings.

We’ve added the Workspace feature.
• For companies, you can now invite your teammates.
• For agencies, you can now create different organizations for your clients.

We’ve completed a full dashboard overhaul.

We’ve added a warm transfer feature.
If you need to provide background information and hand off the call to the next agent, this feature allows you to set up a prompt or static message for smooth transitions.

We’ve added a toggle to disable transcript formatting. This can help resolve the ASR (Automatic Speech Recognition) errors we recently discovered:
If you encounter issues related to number transcription, try out this toggle.

If you’ve added custom fields in Cal.com, you can now use them in Retell.
When using Cal.com functions, you can instruct the agent to collect specific information, and it will automatically display the collected data in the booking event.
1. More Languages

We’ve now supported more languages:
Simply change the language in the settings panel on the agent creation page.

You can now set the maximum duration for calls in minutes to prevent spam.

You can set the duration for detecting voicemail. In some B2B use cases, there are welcome messages before going to voicemail. Setting a longer voicemail detection time can solve this issue.

You can adjust the LLM Temperature to get more varied results. The default setting is more deterministic and provides better function call results.

You can now control the volume of the agent’s voice.

Guide the voice agent through IVR systems with button presses (e.g., “Press 1 to reach support”).

You can now integrate Retell AI with your telephony providers, using your own phone numbers (e.g., Twilio, Vonage). This works with both Retell LLM and Custom LLM.
Integration options:

You could make a multilingual agent who could speak English and Spanish at the same time.

You can also control how certain words are pronounced. This is useful when you want to make sure certain uncommon words are pronounced correctly.
We’ve added new settings for voice model selection:
We have upgraded our audio infrastructure to WebRTC, moving away from the original websocket-based system. This change ensures better scalability and reliability:
We've introduced the updates in our Call API V2, which now separates phone call and web call objects and includes a few field and API changes:

In response to abuse and misuse of our platform, we added some usage limits accordingly:
We've obtained the Vanta SOC 2 Type 1 certification and are currently awaiting the SOC 2 Type 2 certification.


Click on "Test LLM" to enter debugging mode. It works with both single prompts and stateful multi-prompt agents. Now, you can test the LLM without speaking. You can create, store, and edit the conversation.
Pro tip:
For multi-states prompt agent, you can change the starting point to the middle state and test from there.
Your stability is our top priority. We've added the capability to specify a fallback for TTS. In case of an outage with one provider, your agent can use another voice from a different provider.

The OpenAI GPT-4o LLM is now available on Retell. The voice interface API has not been released yet, but we plan to integrate it as soon as it becomes available. Stay tuned!
The pricing for GPT-4o is $0.10 per minute (optional).

You can now guide the model to pronounce a word, name, or phrase in a specific way. For example: "word": "actually", "alphabet": "ipa", "phoneme": "ˈæktʃuəli".
This feature is currently available only via the API but will soon be added to the dashboard.

Normalize the some part of text (number, currency, date, etc) to spoken to its spoken form for more consistent speech synthesis.
Now you could set if users stay silent for a period after agent speech, then end the call.
The minimum value allowed is 10,000 ms (10 s). By default, this is set to 600000 (10 min).

Techcrunch

Call Analysis: We've introduced metrics like Call Completion Status, Task Completion Status, User Sentiment, Average End-to-End Latency, and Network Latency for comprehensive monitoring. You can access these directly on the dashboard or through API.
Disconnection Reason Tracking: Get insights into call issues with the addition of "Disconnection Reason" in the dashboard and "get-call" object. For more details, refer to our Error Code Table.
Function Call Tracking: Transcripts now include function call results, offering a seamless view of when and what outcomes were triggered. Available in the dashboard and get-call API. For custom LLM users, can use tool call invocation event and tool call result event to pass function calling results to us, so that you can utilize the weaved transcript and can utilize dashboard to view when your function is triggered.
Reminder Settings: You can now configure reminder settings to define the duration of silence before an agent follows up with a response. Learn more.
Backchanneling: Backchannel is the ability for the agent to make small noises like “uh-huh”, “I see”, etc. during user speech, to improve engagement of the call. You can set whether to enable it, how often it triggers, what words are used. Learn more.
“Read Numbers Slowly”: Optimize the reading of numbers (or anything else) by making sure it is read slowly and clearly. How to Read Slowly.
Metadata Event for Custom LLM: Pass data from your backend to the frontend during a call with the new metadata event. See API reference.
Improved async OpenAI performance for better latency and stability. Highly recommended for existing Python Custom LLM users to upgrade to the latest version.
Improved webhook security with the signature "verify" function in the new SDK. Find a code example in the custom LLM demo repositories and in the documentation.
Additionally, the webhook includes a temporary recording for users who opt out of storage; please note that this recording will expire in 10 minutes.
We’ve got a shout out in the latest episode of Y Combinator’s podcast Lightcone.


LLM Model Options: Choose between GPT-3.5-turbo and GPT-4-turbo, with additional models coming soon. Available through both our API and dashboard.
Interruption Sensitivity Slider: Adjust how easily users can interrupt the agent. This feature is now accessible in our API and dashboard.
We've updated our pricing structure to be clearer and more modular.
Conversation voice engine API
- With OpenAI / Deepgram voices ($0.08/min)
- With Elevenlabs voices ($0.10/min)
LLM Agent
- Retell LLM - GPT 3.5 ($0.02/min )
- Retell LLM - GPT 4.0 ($0.2/min )
- Custom LLM (No charge)
Telephony
- Retell Twilio ($0.01/min )
- Custom Twilio (No charge)

Dashboard Updates: The history tab now includes a public log, essential for debugging and understanding your agent's current state, tool interactions, and more.
Enhanced API Responses: Our get-call API now provides latency tracking for LLM and websocket roundtrip times.
Ensure the authenticity of requests with our new IP verification feature. Authorized Retell server IPs are: 13.248.202.14, 3.33.169.178.
Enhancements for Custom LLM Users
Web Call Frontend Upgrades
SDK improvement: Our updated SDK maintains backward compatibility, ensuring smooth transitions and consistent performance.

Low Latency, Conversational LLM with Reliable Function Calls
Experience lightning-fast voice AI with an average end-to-end latency of just 800ms with our LLM, mirroring the performance featured in the South Bay Dental Office demo on our website. Our LLM has been fine-tuned for conciseness and a conversational tone, making it perfect for voice-based interactions. It is also engineered to reliably initiate function calls.
Single-Prompt vs. Stateful Multi-Prompt Agents
We provide two options for creating an agent. The Single-Prompt Agent is ideal for straightforward tasks that require a brief input. For scenarios where the agent's prompt is lengthy and the tasks are too complex for a single input to be effective, the Stateful Multi-Prompt Agent is recommended. This approach divides the prompt into various states, each with its own prompt, linked by conditional edges.
User-Friendly UI for Agent Creation and API for Programmatic Agent Creation
Our dashboard allows you to quickly create an LLM agent using prompts and the drag-and-drop functionality for stateful multi-prompt agents. You can seamlessly build, test, and deploy agents into production using our dashboard or achieve the same programmatically via our API.
Pre-defined Tool Calling Abilities such as Call Transfer, Ending Calls, and Appointment Booking
Leverage our pre-defined tool calling capabilities, including ending calls, transferring calls, checking calendar availability (via Cal.com), and booking appointments (via Cal.com), to easily build real-world actions. We also offer support for custom tools for more tailored actions.
Maintaining Continuous Interaction During Actions That Take Longer
To address delays in actions that require more time to complete, you can activate this feature. It enables the agent to maintain a conversation with the user throughout the duration of the function call. This ensures the voice AI agent keeps the interaction smooth and avoids awkward silences, even when function calls take longer.
.gif)
Please note, the previous SDK version will be phased out in 60 days. We encourage you to transition to the latest SDK version.
Stay informed with system status on our new status page.
To streamline your troubleshooting process, we've introduced a public log within our get-call API. This new feature aids in quicker issue resolution and smoother integration, detailed further at the link below.

Thanks to recent cost reductions in our premium voice service, we're excited to pass these savings on to our customers. We're pleased to announce a new, lower price for our premium voice service—now just $0.12 per minute, down from $0.17. Enterprise pricing will also see similar reductions (please contact us at founders@retellai.com for more information).
Please note: The adjusted pricing will take effect from March 1st, and billing will be charged at the end of this month.

Gain more control over your voice output with new dashboard settings.
Tailor your voice interactions to suit your precise needs and preferences for a truly personalized experience.

Boost your communication security with our new webhook signatures. This feature enables you to confirm that any received webhook genuinely comes from Retell, providing an additional layer of protection.
We're excited to announce the launch of our multilingual version, now supporting German, Spanish, Hindi, Portuguese, and Japanese. Access and set your preferred language through our dashboard.
While this feature is currently available via API, we're working on extending support to our SDKs shortly.

Based on user feedback, we've introduced an opt-out option for storing transcripts and recordings. This feature, available in our API and the Playground, gives you more control over your data and privacy.

Dear Retell Community,
We are excited to share several updates and new features with you. Our goal is to continually improve our offerings to better meet your needs. Here's what's new:
We're excited to announce the availability of our discounted enterprise tiered pricing. For more information on that, please contact our team at founders@retellai.com.
We've launched improvements to further reduce latency (by approximately 30%). Try our demo on the website again and experience the magical speed.
We've introduced additional control parameters for agents for greater customization and control. Including:
These parameters have been added to our API. Documentation is being updated, and we are also working on incorporating these features into the SDKs. For more details, visit Create Agent API Reference.
This parameter enables the automatic termination of calls following a specified duration of user inactivity. It's designed to streamline operations and improve efficiency.
To enhance the utility of our transcripts, we are now including word-level timestamps. This feature is pending documentation updates, so stay tuned for more information at Audio WebSocket API Reference.
For users utilizing web calls, our latest client JavaScript SDK (version 1.3.0) now supports auto-reconnection of the socket in case of network disconnections. This ensures a more reliable and uninterrupted service.
We are dedicated to providing you with the best possible service and experience.
We welcome your feedback and are here to support you in making the most out of these new features.
Best regards,
Retell AI team 💛

Please note that our domain has changed. Make sure to update your bookmarks and records to stay connected with us seamlessly.

We've introduced Deepgram as our new TTS provider. Explore it on the Dashboard and discover your favorite one! The price is still $0.10/minute($6/h)
Also, we've added more voice choices from 11labs, ensuring more stable and diverse voice options for your projects.

Gain control over the stability and variability of your voice output, allowing for more tailored and dynamic audio experiences.
Enhance interactions with the ability for the agent to backchannel, using phrases like "yeah" and "uh-huh" to express interest and engagement during conversations.
By popular demand, our Python backend demo has transitioned to FastAPI. It includes Twilio integration and a simple function calling example, providing a more robust and user-friendly experience.
Our updated web frontend SDK makes integration easier and improves performance, allowing you to access live transcripts directly on your web frontend.
Our product now offers improved performance even in noisy settings, ensuring your voice interactions remain clear and uninterrupted.

Dear Retell Community,
We are thrilled to announce a new and significantly more affordable pricing tier featuring OpenAI's TTS. Effective immediately, you can take advantage of our state-of-the-art voice conversation API with OpenAI TTS at the new rate of $0.10 per minute.
This adjustment reflects our commitment to providing you with exceptional value and enhancing your voice interaction experience.
We believe this new pricing will make our product more accessible and allow you to leverage our technology for a wider range of applications.

We updated our SDK, so update your retell SDK to stay in the loop.
- https://www.npmjs.com/package/retell-sdk
- https://pypi.org/project/retell-sdk/
We added a frontend js SDK to abstract away the details of capturing mic and setting up playback.
- https://www.npmjs.com/package/retell-client-js-sdk
We update our documentation at https://docs.re-tell.ai/guide/intro to help people integrate.
We open sourced the LLM and twilio codes that powers our dashboard as a demo:
Node.js demo:
https://github.com/adam-team/retell-backend-node-demo
Python demo:
GitHub - adam-team/python-backend-demo
We open sourced the web frontend demo:
React demo using SDK :
GitHub - adam-team/retell-frontend-reactjs-demo
React demo using native JS:

Dear Retell Community,
In our quest to deliver a human-level conversation experience, we've made a strategic decision to refocus our efforts on voice conversation quality, while scaling back on certain other nice-to-haves. The current API will be phased out after this Wednesday at 12:00 PM. We warmly invite you to adopt our new API, designed to continue providing you with a magical AI conversation experience long-term.
🌟 Key Changes:
🌟 New Features:
We understand that this transition may require adjustments in your current setup, and we are here to support you through this change. Please feel free to reach out to us for any assistance or further information regarding the new API.
Thank you for your understanding and continued support.
Best regards,
Retell AI Team 💛

Dear Retell Community,
We are thrilled to announce a new and significantly more affordable pricing tier featuring OpenAI's TTS. Effective immediately, you can take advantage of our state-of-the-art voice conversation API with OpenAI TTS at the new rate of $0.10 per minute.
This adjustment reflects our commitment to providing you with exceptional value and enhancing your voice interaction experience.
We believe this new pricing will make our product more accessible and allow you to leverage our technology for a wider range of applications.
We updated our SDK, so update your retell SDK to stay in the loop.
- https://www.npmjs.com/package/retell-sdk
- https://pypi.org/project/retell-sdk/
We added a frontend js SDK to abstract away the details of capturing mic and setting up playback.
- https://www.npmjs.com/package/retell-client-js-sdk
We update our documentation at https://docs.re-tell.ai/guide/intro to help people integrate.
We open sourced the LLM and twilio codes that powers our dashboard as a demo:
Node.js demo:
https://github.com/adam-team/retell-backend-node-demo
Python demo:
GitHub - adam-team/python-backend-demo
We open sourced the web frontend demo:
React demo using SDK :
GitHub - adam-team/retell-frontend-reactjs-demo
React demo using native JS:
GitHub - adam-team/retell-frontend-reactjs-native-demo
Thank you for your understanding and continued support.
Best regards,
Retell AI Team 💛

Dear Retell Community,
We are thrilled to announce a new and significantly more affordable pricing tier featuring OpenAI's TTS. Effective immediately, you can take advantage of our state-of-the-art voice conversation API with OpenAI TTS at the new rate of $0.10 per minute.
This adjustment reflects our commitment to providing you with exceptional value and enhancing your voice interaction experience.
We believe this new pricing will make our product more accessible and allow you to leverage our technology for a wider range of applications.
We updated our SDK, so update your retell SDK to stay in the loop.
- https://www.npmjs.com/package/retell-sdk
- https://pypi.org/project/retell-sdk/
We added a frontend js SDK to abstract away the details of capturing mic and setting up playback.
- https://www.npmjs.com/package/retell-client-js-sdk
We update our documentation at https://docs.re-tell.ai/guide/intro to help people integrate.
We open sourced the LLM and twilio codes that powers our dashboard as a demo:
Node.js demo:
https://github.com/adam-team/retell-backend-node-demo
Python demo:
GitHub - adam-team/python-backend-demo
We open sourced the web frontend demo:
React demo using SDK :
GitHub - adam-team/retell-frontend-reactjs-demo
React demo using native JS:
GitHub - adam-team/retell-frontend-reactjs-native-demo
Thank you for your understanding and continued support.
Best regards,
Retell AI Team 💛



